
发表日期:2017-07-04
眼见不为实:艺术家用人工智能技术生成了有图有视频的……假新闻!
—— 今年早些时候,某著名视频网站上有人放出了一段看上去像是法国著名音乐人弗朗索瓦丝·哈蒂(Françoise Hardy)的视频。在这个视频中,她被画面外的人...
作者:economist.com
今年早些时候,某著名视频网站上有人放出了一段看上去像是法国著名音乐人弗朗索瓦丝·哈蒂(Françoise Hardy)的视频。在这个视频中,她被画面外的人问了个问题,是关于为什么川普要指使白宫发言人肖恩·斯宾塞,让他在总统就职典礼的观礼人数问题上撒谎。一开始哈蒂还争辩了几句,接下来她表示,斯宾塞先生“提出了另外一种事实”。
整个视频有点奇怪,不仅仅是因为这位弗朗索瓦丝·哈蒂看上去只有20岁左右(她本应该73岁了),还因为视频中她的嗓音,实际属于特朗普的顾问凯莉安·康威(Kellyanne Conway)。

这段名为《另一张面孔 v1.1》的视频,是德国艺术家马里奥·克林格曼搞出来的一个艺术作品。在这个作品中,哈蒂的数字化幻象口中说出的是康威回答NBC记者提问的话语。整个视频模模糊糊,摇摆不定,任何一个正常的视觉特效工作室都能做的比这个好得多。
但克林格曼并不是拿什么编辑软件自己瞎搞出这段视频的。相反,他在自己家的电脑上使用了一种叫生成式对抗网络(generative adversarial network,GAN)的机器学习算法,并“喂”了大量哈蒂年轻时期的MTV视频给这个程序,让电脑花了几天时间,自动弄出了这么一个东西出来。
克林格曼本人非常热衷于使用机器学习调教出一堆软件来帮他做这种“创意生产”。虽然他现在弄出来的作品多多少少有点……扭曲,比如这样:
或者这样:

克林格曼的实验预示着真实与谎言的永恒战斗又开辟了一块新的战场。因为所谓“假新闻”的散播,在某些领域里,白字黑字已经不足为凭了,但照片和录音还是保持着它们固有的可靠性。然而,现在以GAN为代表的机器学习技术正在不断动摇着这个可靠性。
音频很容易伪造。通常情况下,计算机将许多预先录好的短小语音片段连接起来,生成一句完整的语音。包括Siri在内的各种虚拟语音助手都是这么做的。但是这样生成的数码语音,其合成质量受到预先存储的语音片段的限制,只有说特定的句子时才会显得非常逼真。

生成式语音的机制则颇为不同。使用神经网络学习源语音中的统计特征,并在给定的任意内容上重构这些特征,这种对语音的模拟不再是以秒为单位,而是以毫秒级的速度进行模拟。比如你想要让特朗普或者任何一个公众人物说什么话,你先拿大量此人的语音信息,输入到一个深度学习算法中进行训练,最后只要告诉这个已经训练完的程序,你想让这个人说什么即可。
去年至今,Google 在英国的 DeepMind,百度在硅谷的深度学习研究院以及蒙特利尔学习算法研究所(MILA)等各种机构,都发布了拟真度超高的文本生成语音算法。目前这些算法所需要的计算机运算能力只有大型技术企业能拥有,但这种情况并不会持续太久。

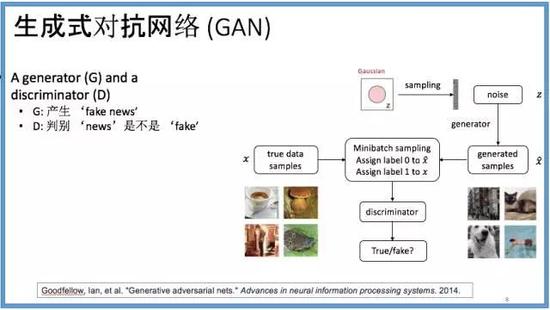
生成图像则难得多。“生成式对抗网络”的机器学习方式,是在2014年由伊恩·古德费洛(Ian Goodfellow)提出的,当时他是在深度学习之父约书亚·本吉奥(Yoshua Bengio)手下读博的学生。古德费洛发现,虽然深度学习能让机器很好地辨别各种类型的数据(例如区分一张猫照片和一张狗照片),但让软件按照这个去生成猫或者狗的照片则根本一塌糊涂。对电脑来说,就算从数据库里学习了大量的训练图片,要生成一张有意义的照片也是困难重重。

|  |
| 左:约书亚·本吉奥 (Yoshua Bengio) 右:伊恩·古德费洛(Ian Goodfellow) | |
于是,古德费洛采用了另外一个类似的概念:博弈。他不再尝试让计算机一蹴而就,直接生成什么有用的东西,而是用另一个agent——一个对抗者——对生成器的输出进行评判,按照和训练数据集中已有的真实照片的相似度,给出具体的评分来自数据集还是来自生成器的判断。生成器根据辨别器的反馈,不断进行修正,逐步生成越来越像真实的图像。
如今,GAN算法可以从一句描述指令,生成出邮票大小的鸟类图片。告诉算法“这鸟是白色的,头和翅膀上有一些黑色,鸟嘴长,是橘色的”,机器就会生成对应的图片。虽然输出的图片现在还不能算很完美,但粗看起来还是非常逼真的。

虽然邮票大小的鸟类图片还并不足以公众对日常照片的真实性产生恐慌,但技术发展的速度是常人难以想象的。在过去的5年里,类似的深度学习算法在给照片进行分类时的错误率已经从25%下降到只有几个百分点。图像生成的算法预计也会经历类似的过程。
古德费洛现在就职于 Google Brain,Google 内部的人工智能研究部门。他预测,在三年内可能就会出现几乎可以以假乱真的AI生成视频。也许其他专家预期的时间会比他的长,但业内基本认为这只是一个时间问题。“我们认为,人工智能将永远改变我们对于哪些证据是可以信任的看法,”古德费洛表示。
虽然科技驱动了新型的伪造技术,科技也同样提供了破解伪装的办法。一种核实的办法是,要求所有记录数据都应包括生成时的元数据,包括了录制的时间、地点和录制设备等。这类数据使人们得以区分出一张虚假的照片,例如照片上的内容和拍摄现场的时间不符等等。
另一个独特的例子来自英伟达(Nvidia)——它生产的芯片是许多人工智能设备的核心。在2014年,英伟达利用自己的芯片来分析阿波罗11号在登月时拍摄的照片。在模拟了整个场景的光线反射情况之后,英伟达的研究人员证明了巴兹·奥尔德林(Buzz Aldrin)太空服上那些奇怪的亮点确实是在月球上反射了阳光形成的——而不是像某些蠢蛋认为的是什么好莱坞电影摄影棚里留下的作假证据。

国际特赦组织已经在采用类似的做法了。他们的“证据实验室”需要核实一些声称可作为证据的视频和照片,因此他们使用 Google 地球之类的软件来检查照片或视频拍摄地点附近的自然环境背景,看是不是和证据中声称的一致;他们还是用 Wolfram Alpha 之类的搜索引擎,多方查询记录上的天气情况,与证据中显示的进行对比。他们现在已经能区分出把老视频重新包装自称是新的证据的行为,但他们也将面对由程序生成的伪造视频。密码学也能成为对抗伪造的有力武器,可以通过确认文件的特殊数字签名,来判断文件是否是来自于可信任的机构,或是否来自最初生成视频的设备。

有些人早已明白媒体文件作为证据的脆弱性。“尽管对照片真实性的推测能赋予照片以可靠性,但拿着设备的人的个人喜好、有没有受到诱惑等情况呢?摄影师的工作和其他阴暗的商业活动没什么不同,它往往也是在真相和艺术之间徘徊。”苏珊·桑塔格在她的《论摄影》中就这样写道。人工智能生成媒体文件这种做法则在这方面走得更远——反正你们之后也要按自己的意思改的,不如直接跳过要在真实世界里扛着镜头或录音笔的这些“无聊”行为吧?
(本文已投稿给「优达学城」并发表。 原作: economist.com 译者:欧剃 转载请保留此信息)
编译来源: https://www.economist.com/news/science-and-technology/21724370-generating-convincing-audio-and-video-fake-events-fake-news-you-aint-seen
标签:Udacity、Machine-Learning、AI、Translate