
发表日期:2019-05-31
机器学习怎么玩?不如先来盘精灵宝可梦对战?
—— 快让你的朋友们看看,你是如何专业地预测战斗结果,成为伟大的宝可梦训练家吧!
作者:Saurabh Charde

图片来源:The Verge
今天的文章里,我们将使用机器学习技术,对精灵宝可梦(宠物小精灵/神奇宝贝/口袋妖怪)中的对战结果进行预测。特别有趣的是,我们将会预测许多前所未见的战斗,而你也可以通过我们放在 Github 上的 Jupyter Notebook 代码,亲自调教这个 AI!
快让你的朋友们看看,你是如何专业地预测战斗结果,成为伟大的宝可梦训练家吧!
介绍
虽然以前不叫这个名字,但精灵宝可梦系列游戏应该是我们童年中不可或缺的一部分吧。最近,《大侦探皮卡丘》的上映,再次掀起了这一热潮。那么,我们现在面对的问题就是,根据不同宝可梦的属性数据(比如攻击、防御、速度等),预测一些之前未发生过的随机对决的胜负情况。听起来是不是很有趣啊?
不过,在开始之前,让我们先简单介绍一下相关的背景知识。
机器学习
实际上,要预测对战结果,最大的困难在于,我们只熟悉不多的一些宝可梦,而其实整个精灵宝可梦的世界中,存在着超过 800 种以上的宝可梦。这可真不少,对吧?那么,为了预测对战结果,我们就需要研究这所有 800 种宝可梦,观察它们的行动,特殊攻击,以及比赛数据等等。简而言之,需要考虑的东西(数据)实在是太多了,导致我们需要许多天时间,才能获取足够的信息,以便正确预测每场比赛的结果。(没错吧?)
这也就是机器学习技术大显身手的时候啦。当你有非常多的数据,而你需要通过这些数据进行一些预测(比如天气预报,根据症状推测疾病信息等等),那么我们就可以用上机器学习(是不是很简单?)
熟悉数据集
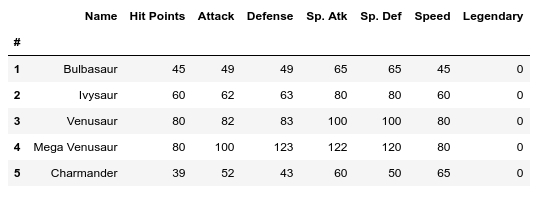
数据集中的前五行数据
数据集,是针对某个特定主题(比如今天我们的例子是宝可梦)的大量数据的集合。这个数据集中提供了许多宝可梦的信息,比如生命值、攻击值、特殊防御以及是否传说宝可梦(是=1,否=0)等。上图显示的是表中前5行的数据,整个数据集总共有 800 个宝可梦的数据(也就是有 800 行)。
看过数据集之后,我们就可以着手准备对它使用机器学习啦。
如何应用机器学习
把大象放进冰箱错了,构建一个机器学习模型,需要 3 个步骤:
-
构建分类器
-
训练分类器
-
测试分类器
构建分类器
注:分类器用来将数据区分成各个不同的类别。比如,给出一张动物图片,将它分类成猫或者狗)
为了从数据中提取信息,我们需要利用一些机器学习的模型(分类器),这些模型基本上可以看作是用来从给定的数据中寻找特定的模式,以便利用数据进行预测的算法(看晕了?继续看下去就好了)。
为了达到这一目的,我们将使用随机森林算法(分类器),它是决策树算法的一个更好的实现。
决策树
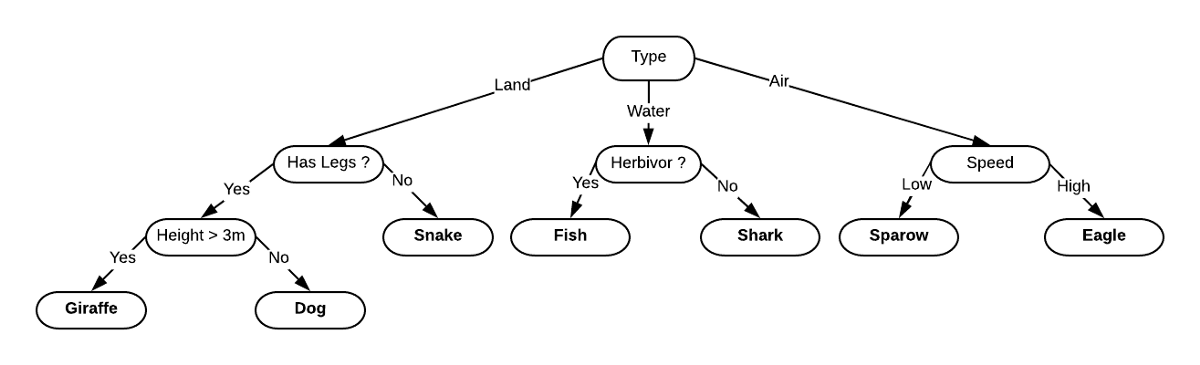
一个分类动物用的简单决策树
假设我们的任务是根据动物的类型、身高、体重或速度等特征来猜测这是什么动物。如上图所示,我们可以使用决策树轻松地对此任务进行建模。因此,在决策树的每个节点上,我们都会问一个问题,并根据答案进一步划分出不同的子树。不断重复这个过程,直到我们能确定这是什么动物为止。因此,对于给定数据集,决策树分类器将在每个点处询问正确的问题(增加信息增益),以便用正确的方式(增加每个预测的置信度)对树进行划分(增加结果的准确性)。
时间复杂度 = O(树的深度)
随机森林
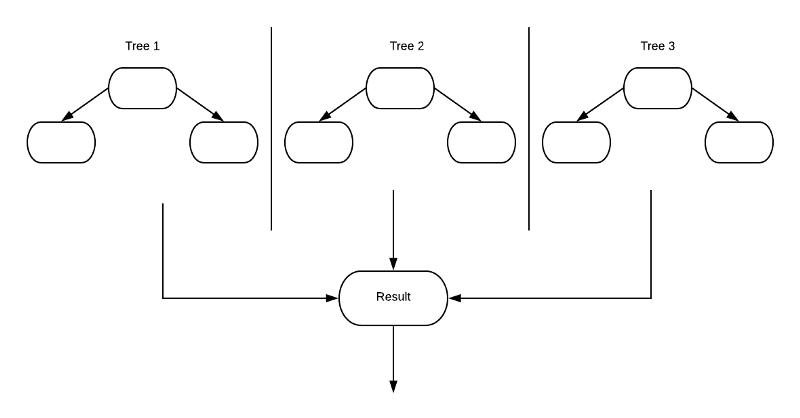
一个简单的随机森林示意图
就像森林是树木的集合那样,随机森林算法也将使用多个决策树,并最终组合每个决策树的结果以预测其最终结果。我们可以把它想象为将多棵树学到的东西合为一体。这种方法能比使用单个决策树提供更准确的结果。
clf = RandomForestClassifier(n_estimators=100)
一个有 100 棵决策树的“森林”
最后,我们用上面这样的代码构建一个随机森林。其中 n_estimators 参数决定了森林中决策树的数量(这里是 100)。
训练分类器
根据我们的任务,两只宝可梦,每个都有一套自己的属性(速度、攻击力,等等),最后的结果中,其中一只将会胜利。
model = clf.fit(x_train, y_train)
pred = model.predict(x_test)
print('准确率 ', accuracy_score(pred, y_test)*100)
# 输出结果:准确率 95.008
训练并检测分类器的准确率
我们在宝可梦数据集(也就是 x_train)上训练(或拟合)我们的分类器,目标是尽可能减小预测值和实际值(y_train)之间的差距。这里的训练意味着发现数据集中不同属性之间的关系,并以此进行预测。
然后,我们对训练出的分类器进行检测,并计算它的预测准确度。当前结果是 95.008%(这意味着这个分类器在 100 场对决中能预测成功 95 个),这对我们来说是一个不错的开始。
到现在,我们已经完成了所有构建、训练分类器的工作,可以让它试试挑战一些真实对决的数据啦。
测试分类器
决战的时刻到了。让我们给分类器一些随机的宝可梦对决数据,让它为我们预测一下战斗结果吧。我们已将所有这些随机对决的数据存储在另一个名为 test_data 的数据集中。
这个数据集差不多长这样:
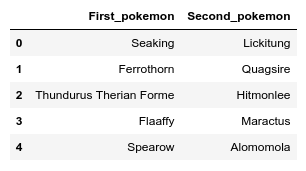
包含测试对决数据的数据集
这两列数据对应的是将要进行对决的宝可梦的名字。我们现在就将这两个宝可梦(的名字…不然呢?)喂给分类器,而我们的算法将最终返回它所预测的,这场战斗中最可能的胜利者。请记住,分类器可不是随机瞎猜的。事实上,它将会仔细分析对战双方的各个参数,以作出最准确的决定(这就是机器学习的力量)。
准备好面对结果了吗?
那么,你觉得 大岩蛇 和 波波 对战,谁会赢?

图片来源: Google 图片
让我们用机器学习模型预测一下吧。

获胜者是大岩蛇
好吧,这场比赛没有什么悬念。让我们再试试其他的。
魔墙人偶 对战 可达鸭,你觉得结果如何?

图片来源: Google 图片
事实上,在宝可梦官方系列中,这两个宝可梦还没有对战记录,所以我们是在预测未来可能发生的战斗!(爽!)
那么,最后结果如何?

获胜者是魔墙人偶
如果你认真仔细地分析一下,你也会发现,魔墙人偶确实会有那么一点获胜的优势。
结语
今天,我们一起探索了这样一个可以用机器学习来解决的,非常基本的问题。本文中涉及的许多概念构成了大多数机器学习方法的基础。我试着用最简单的方式来解释这些概念,这样大家都能对机器学习的工作方式有一个比较清楚的概念,并且能将它用在实际生活当中。
最后,我希望大家能给这篇文章提提建议,分享一下你们自己是怎么接触和使用机器学习算法的吧。
(本文已投稿给「优达学城」。 原作: Saurabh Charde 编译:欧剃 转载请保留此信息)
编译来源: https://medium.com/ai-enigma/predicting-pokemon-battle-winner-using-machine-learning-d1ed055ac50
标签:Udacity、Translate、Machine-Learning