
发表日期:2019-06-12
StanfordNLP,让你在 Python 里一手掌握 53 种自然语言分析
—— 不久之前,斯坦福大学公开了它最新的自然语言处理代码库—— StanfordNLP。它不但包含了完整的语义分析工具链,还带有 73 个不同的高精度神经网络模...
作者:Mohd Sanad Zaki Rizvi
不久之前,斯坦福大学公开了它最新的自然语言处理代码库—— StanfordNLP。它不但包含了完整的语义分析工具链,还带有 73 个不同的高精度神经网络模型,能解析 53 种不同的人类语言。是不是很牛×啊?今天的教程里,优达菌就手把手带你在 Python 上使用 StanfordNLP,进行一些自然语言处理实战。

在学习自然语言处理(NLP)的过程中,我们常常会遇到这样一个问题:“我们能不能为除英语之外的其他语言构建模型呢?”在很长一段时间里,这都是一个难以完成的任务。要知道,每种语言都有自己独特的语法模式和细微的语言差别,而且除了英语之外,其他语言的数据集实在是少之又少。
但如今,我们有了 StanfordNLP 这一神器。
当我第一次看到 StanfordNLP 的介绍时,我简直无法抑制自己的激动之情。作者声称它可以支持超过 53 中不同的人类语言!(没错,你没看错,确实是 53 种……我当时也觉得自己一定是眼花了。)
在 StanfordNLP 的官方网站上,作者列出了目前支持的所有 53 种人类语言,其中包含了许多其他 NLP 库所没有的语言,比如印地语、日语和我们最爱的中文。这简直是为我们打开了通往无限可能的新世界的大门啊!

StanfordNLP 到底是何方神圣,我为啥需要用它?
简单地说,StanfordNLP 是一系列预训练好的,高水平的神经网络模型。目前的 73 个模型都是来自 2017、18 年 CoNLL 会议上的研究者。它们都是用 PyTorch 训练而来的,你也可以用自己的语料库来训练和评估它们,是不是很酷炫?

此外,StanfordNLP 还包含了一个官方的 CoreNLP 封装。CoreNLP 作为一款广受好评的史诗级 NLP 库,在此之前,你只能依靠 Java 才能用上它。对有兴趣的读者,我建议你看看这个教程,了解更多有关 CoreNLP 的信息,以及它在 Python 中的工作原理。
对 NLP 爱好者来说,真是没有比这个更棒的了。现在,就让我们在 Python 中实际操作一下吧!
在 Python 中安装设置 StanfordNLP 库
最初,这个库里有一些奇怪的东西,让我感到十分困惑。例如,你需要使用 Python 3.6 / 3.7 或更高版本才能使用 StanfordNLP。为了安全起见,我在 Anaconda 中设置了一个单独的 Python 3.7.1 环境。具体步骤如下:
-
打开 conda 命令行,输入:
conda create -n stanfordnlp python=3.7.1一般来说一路 yes 到底即可。
-
接着激活刚建立的环境:
source activate stanfordnlpconda 4.6 或更高版本可以用:
conda activate stanfordnlp -
在新环境里安装 StanfordNLP 库:
pip install stanfordnlp -
接下来,我们需要下载对应自然语言的模型。打开一个 Python 命令行,导入 StanfordNLP 库:
import stanfordnlp接着下载对应的语言模型,以英语(“en”)为例:
stanfordnlp.download('en')根据你网络速度的不同,这可能需要花费一些时间。一般来说你得下载大概 300M 的内容。
一些注意事项
-
StanfordNLP 是基于 PyTorch 1.0.0 构建的。如果你尝试在更早的版本上运行它,可能会遇到一些奇怪的问题。你可以在命令行运行这样的命令来检查你的 PyTorch 版本:
pip freeze | grep torch正常情况下你应该看到类似
torch==1.0.0这样的输出。 -
我试过在没有独立显示芯片的机器上跑这个库,比如我的联想 Thinkpad E470(8G 内存,英特尔核显)。
结果是,Python 很快就甩了一个 memory error 给我。因此,我换到一台有独立显卡的机器上来运行这些代码,我强烈建议你也这么做。
对了,你可以试试 Google 出品的地表最强 Python 编辑器——Google Colab,它提供了 12-14G 的内存,以及免费的 GPU 算力。
好啦,说了这么多,你应该已经装好了相关的库和模型了吧?让我们试着开始一些基本的 NLP 处理吧。
使用 StanfordNLP 完成简单的 NLP 任务
假设我们要分析一段英文材料,首先,我们需要建立一个文字处理管道(pipeline):
nlp = stanfordnlp.Pipeline(processors = "tokenize,mwt,lemma,pos")
doc = nlp("""The prospects for Britain’s orderly withdrawal from the European Union
on March 29 have receded further, even as MPs rallied to stop a no-deal scenario.
An amendment to the draft bill on the termination of London’s membership of the
bloc obliges Prime Minister Theresa May to renegotiate her withdrawal agreement
with Brussels. A Tory backbencher’s proposal calls on the government to come up
with alternatives to the Irish backstop, a central tenet of the deal Britain agreed
with the rest of the EU.""")
我们通过 processors = "" 参数指定需要分析的具体任务。如果不传入任何参数,程序将默认调用全部 5 个处理模块进行分析。具体可见下表:
| 参数名 | 标注器类名(Annotator) | 工作方式/结果 |
|---|---|---|
| tokenize | TokenizeProcessor | 分词工具。它将一个文档( Document )分成许多句子( Sentence ),每个句子都包含着一个分词结果的列表,列表的元素是 Token。分词处理器还会预测哪些单词/字会组成多字词/词组,以便后续用 MWT 处理模块进行扩展。 |
| mwt | MWTProcessor | 对上一步预测的多字词/词组进行处理,将它们进行扩展。 |
| lemma | LemmaProcessor | 利用单词( Word )的 Word.text 和 Word.upos 属性,对每个单词进行词形还原。处理结果将存放在 Word.lemma 中。 |
| pos | POSProcessor | 对每个 token 都进行全局词性分析(universal POS,UPOS)和基于语料库的词性分析(treebank-specific POS,XPOS) 标注,以及全局的形态特征(universal morphological features ,UFeats)标注,最后存放在 Word 对象的 pos 、 xpos 以及 ufeats 属性中。 |
| depparse | DepparseProcessor | 它提供了一个准确的句法依存关系解析器,用来确定句子中每个单词的句法核心(syntactic head),以及两个单词之间的依存关系。分析结果保存在 Word 对象的 governor 和 dependency_relation 属性中。 |
表格内容翻译自 StanfordNLP 项目主页
让我们在实战中检验一下这些分析器吧。
分词处理
当 TokenizeProcessor 运行的时候,分词处理过程将在后台运行,事实上,它的处理速度相当快。你可以使用 print_tokens() 方法来查看分词结果:
doc.sentences[0].print_tokens()
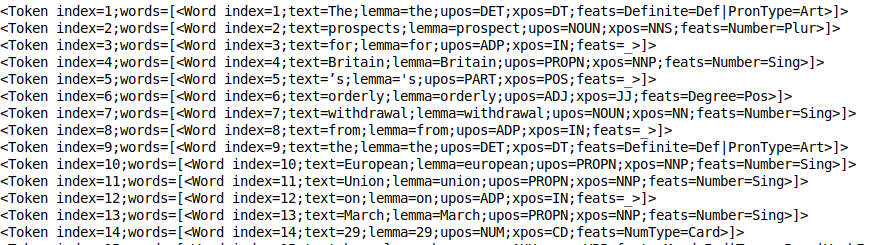
结果就类似上面这样。每个 token 对象都包含了句子中每个词的索引,以及一个包含了 Word 对象的列表(以防有一些由多个单词/字组成的短语/词组。每一个 Word 对象都包含了详细的信息,包括序号、单词原形、词性、形态特征等标签。
词形还原
这就要用到 LemmaProcessor 给每个 Word 对象生成的 lemma 属性了(参见上面分词结果图中的 lemma= 部分)。我们只需要简单的几行代码就可以对所有单词进行词形还原:
# 文件名: lemma.py
import pandas as pd
def extract_lemma(doc):
parsed_text = {'word':[], 'lemma':[]}
for sent in doc.sentences:
for wrd in sent.words:
# 提取文本和原形
parsed_text['word'].append(wrd.text)
parsed_text['lemma'].append(wrd.lemma)
# 返回值是一个 DataFrame 对象
return pd.DataFrame(parsed_text)
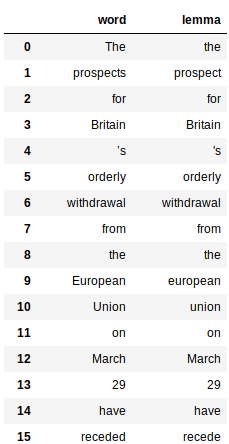
extract_lemma(doc)
这将返回一个 pandas 的数据表(DataFrame 对象),列出了每个单词及其对应的单词原形:
词性分析与标注
用于词性分析的 POSProcessor 可以又快又准地处理多种不同语言。和词形还原一样,词性分析的标签也很容易读取和输出:
# 文件名: parts_of_speech.py
# 定义一个存放 POS 值及对应词性描述的字典对象
pos_dict = {
'CC': 'coordinating conjunction',
'CD': 'cardinal digit',
'DT': 'determiner',
'EX': 'existential there (like: \"there is\" ... think of it like \"there exists\")',
'FW': 'foreign word',
'IN': 'preposition/subordinating conjunction',
'JJ': 'adjective \'big\'',
'JJR': 'adjective, comparative \'bigger\'',
'JJS': 'adjective, superlative \'biggest\'',
'LS': 'list marker 1)',
'MD': 'modal could, will',
'NN': 'noun, singular \'desk\'',
'NNS': 'noun plural \'desks\'',
'NNP': 'proper noun, singular \'Harrison\'',
'NNPS': 'proper noun, plural \'Americans\'',
'PDT': 'predeterminer \'all the kids\'',
'POS': 'possessive ending parent\'s',
'PRP': 'personal pronoun I, he, she',
'PRP$': 'possessive pronoun my, his, hers',
'RB': 'adverb very, silently,',
'RBR': 'adverb, comparative better',
'RBS': 'adverb, superlative best',
'RP': 'particle give up',
'TO': 'to go \'to\' the store.',
'UH': 'interjection errrrrrrrm',
'VB': 'verb, base form take',
'VBD': 'verb, past tense took',
'VBG': 'verb, gerund/present participle taking',
'VBN': 'verb, past participle taken',
'VBP': 'verb, sing. present, non-3d take',
'VBZ': 'verb, 3rd person sing. present takes',
'WDT': 'wh-determiner which',
'WP': 'wh-pronoun who, what',
'WP$': 'possessive wh-pronoun whose',
'WRB': 'wh-abverb where, when',
'QF' : 'quantifier, bahut, thoda, kam (Hindi)',
'VM' : 'main verb',
'PSP' : 'postposition, common in indian langs',
'DEM' : 'demonstrative, common in indian langs'
}
def extract_pos(doc):
parsed_text = {'word':[], 'pos':[], 'exp':[]}
for sent in doc.sentences:
for wrd in sent.words:
if wrd.pos in pos_dict.keys():
pos_exp = pos_dict[wrd.pos]
else:
pos_exp = 'NA'
parsed_text['word'].append(wrd.text)
parsed_text['pos'].append(wrd.pos)
parsed_text['exp'].append(pos_exp)
return pd.DataFrame(parsed_text)
extract_pos(doc)
注意到上面那个巨大的字典对象了吗?那是为了把词性分析的标签和人类能懂的描述一一对应起来。这能让我们更好地理解文件的语法结构。
程序将输出一个数据表对象,其中包含 3 列:单词(Word)、词性(pos)以及对应的解释(exp)。解释列中的内容包含了最多的语义信息,也是对我们最有用的部分。
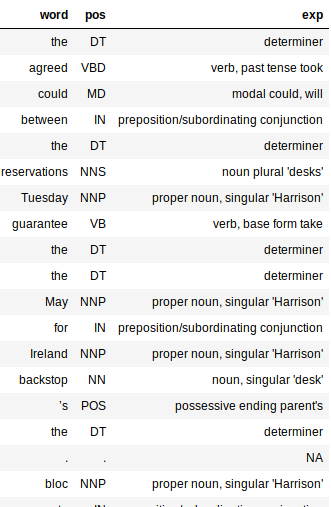
增加了解释列之后,我们就能更容易地看出分析器处理词句时的准确性如何。让我欣喜的是,绝大部分的词语都能够被正确地标记起来,它甚至能正确地判断出一个词的时态和词性,包括它是单数还是复数形式等。
依存关系解析
依存关系解析也是 StanfordNLP 里开箱即用的工具之一。你只需要在程序中调用 print_dependencies() 方法,就能方便地获取到句子中所有元素的依存关系:
doc.sentences[0].print_dependencies()

总的来说,程序将在一次管道处理过程中计算上述的每一个步骤。对于能使用 GPU 的机器来说,整个运算过程一般要不了几分钟就能搞定。
于是,我们已经摸清了用 StanfordNLP 库完成简单文字处理任务的基本操作,现在我们该试试在各种不同语言上进行同样的操作啦!
对印地语使用 StanfordNLP 进行处理
StanfordNLP 在处理性能和多语言文本解析支持方面都拥有非常突出的表现。我们现在就来深入研究一下后面这部分。
处理印地语文字(梵文文本)
首先,我们先下载印地语的模型(相对来说小多了!):
stanfordnlp.download('hi')
接着,把一段印地语文字放进去,作为目标文本:
hindi_doc = nlp("""केंद्र की मोदी सरकार ने शुक्रवार को अपना अंतरिम बजट पेश किया. कार्यवाहक वित्त मंत्री पीयूष गोयल ने अपने बजट में किसान, मजदूर, करदाता, महिला वर्ग समेत हर किसी के लिए बंपर ऐलान किए. हालांकि, बजट के बाद भी टैक्स को लेकर काफी कन्फ्यूजन बना रहा. केंद्र सरकार के इस अंतरिम बजट क्या खास रहा और किसको क्या मिला, आसान भाषा में यहां समझें""")
要生成所有的标签,这样就已经足够了,让我们检查一下吧:
extract_pos(hindi_doc)
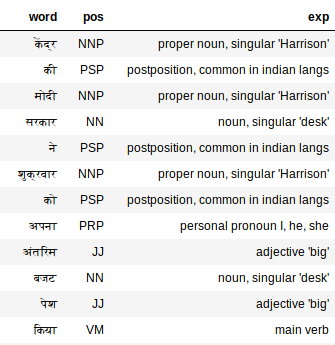
毫不意外,词性分析器很完美地处理了印地语文本。看看这个“अपना”吧,词性分析器指出这是个人称代词(我、他、她),这还是比较准确的。
调用 CoreNLP 的 API 进行文字分析
CoreNLP 是一个久经考验的工业级自然语言处理工具集,它的高性能和准确性都是相当有名的。要想调用 CoreNLP 复杂的 API,你只需要在 StanfordNLP 里写上三行代码。你没看错,确实只需要 3 行代码就能设置好了!
-
打开冰箱门不,是下载 CoreNLP 包。打开你的 Linux 终端,输入以下命令:wget http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip -
解压下载好的软件包:
unzip stanford-corenlp-full-2018-10-05.zip -
启动 CoreNLP 服务器:
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000
注意: CoreNLP 需要 Java8 才能运行,请务必确保你已经安装好了 JDK 和 JRE 1.8.x 以上版本。
接着,你需要让 StanfordNLP 获取到 CoreNLP 所在的路径。你需要把 CoreNLP 的路径写入环境变量 $CORENLP_HOME 中。在我上面的例子中,CoreNLP 所在的文件夹是直接放在用户的 home 目录中,所以我的环境变量是这样:
export CORENLP_HOME=stanford-corenlp-full-2018-10-05/
上面的准备工作完成之后,你就可以启动服务进程,并用 Python 代码给它发送请求。接下来,我们将启动服务器,设置客户端,发送处理请求,并最后从返回的对象中获取所需的数据。让我们一起看看这个综合性的实例吧。
1. 构建一个 CoreNLP 客户端
# 文件名: corenlp_setup.py
from stanfordnlp.server import CoreNLPClient
# 输入实例文本
print('---')
print('input text')
print('')
text = "Chris Manning is a nice person. Chris wrote a simple sentence. He also gives oranges to people."
print(text)
# 显示服务器启动信息
print('---')
print('starting up Java Stanford CoreNLP Server...')
# 启动客户端进程
with CoreNLPClient(annotators=['tokenize','ssplit','pos','lemma','ner','depparse','coref'],
timeout=30000, memory='16G') as client:
# 把处理请求发送给服务器
ann = client.annotate(text)
# 获取返回对象的第 1 个句子
sentence = ann.sentence[0]
2. 依存关系分析及词性分析
# 文件名: corenlp_depparse.py
# 获取第 1 个句子的依存关系
print('---')
print('dependency parse of first sentence')
dependency_parse = sentence.basicDependencies
print(dependency_parse)
# 获取第 1 个句子中的第 1 个词
print('---')
print('first token of first sentence')
token = sentence.token[0]
print(token)
# 词性分析结果
print('---')
print('part of speech tag of token')
token.pos
print(token.pos)
3. 命名实体识别(NER)与共指链(Co-Reference Chains)的解析
# 文件名: corenlp_ner.py
# 获取命名实体标签
print('---')
print('named entity tag of token')
print(token.ner)
# 获取句子中的第 1 个实体指称语(entity mention)
print('---')
print('first entity mention in sentence')
print(sentence.mentions[0])
# 获取共指链
print('---')
print('coref chains for the example')
print(ann.corefChain)
# 用正则表达式模板查找 wrote 对应的主语
pattern = '([ner: PERSON]+) /wrote/ /an?/ []{0,3} /sentence|article/'
matches = client.tokensregex(text, pattern)
# sentences 中包含了每一条匹配到的句子
assert len(matches["sentences"]) == 3
# 检查 length 的值,你就知道是否有成功匹配到
assert matches["sentences"][1]["length"] == 1
# 像大部分正则分组一样,你可以直接获取匹配到的文字
matches["sentences"][1]["0"]["text"] == "Chris wrote a simple sentence"
matches["sentences"][1]["0"]["1"]["text"] == "Chris"
# 还可以用 semgrex 表达式直接查找结果
pattern = '{word:wrote} >nsubj {}=subject >dobj {}=object'
matches = client.semgrex(text, pattern)
# sentences 中包含了每一条匹配到的句子
assert len(matches["sentences"]) == 3
# 检查 length 的值,你就知道是否有成功匹配到
assert matches["sentences"][1]["length"] == 1
# 像大部分正则分组一样,你可以直接获取匹配到的文字
matches["sentences"][1]["0"]["text"] == "wrote"
matches["sentences"][1]["0"]["$subject"]["text"] == "Chris"
matches["sentences"][1]["0"]["$object"]["text"] == "sentence"
在 Python 中使用 CoreNLP 的时候,我最喜欢的就是它带来的方便与易用。
个人认为,StanfordNLP 的优势与不足之处
考虑到未来的使用前景,StanfordNLP 最让我兴奋的优势有:
- 在许多不同的语言分析上,都能做到开箱即用
- 事实上,它将成为官方的 Python 语言 CoreNLP 接口,这意味着它今后使用会越来越方便,功能也会越来越强大。
- 虽然内存开销相当大,但总体来说运算速度非常快。
- 在 Python 中能方便直观地运行与调试它。
然而,还是有一些问题需要解决。以下是我对 StanfordNLP 需要改进的地方的看法:
- 语言模型的下载量略微嫌大了点(虽然已经从原来英文1.9GB/中文1.8GB下降到现在的 244MB / 234MB,但考虑到网络情况,总的来说还是要花上比较久的时间)。
- 还是需要大量的代码来形成可用的功能。比起 NLTK 那种能快速编写原型脚本的库来说,StanfordNLP 还有很长的路要走。
- 目前还缺少可视化功能,而这对依存关系分析还是非常有用的。与 SpaCy 之类的库相比,StanfordNLP 在这方面还存在着短板。
最后,希望你认真地看一看 StanfordNLP 的官方文档——从本文发布到现在,说不定又有新的变化了呢。
结语
就目前来说,类似 CoreNLP 这样神奇的工具正在积极拥抱 Python 软件生态系统,斯坦福这样的科研巨头也正在努力开源他们的软件,这让我对未来抱着乐观的态度。
确实,StanfordNLP 刚发布 0.2.0 版本不久。虽然这次的版本显著地缩小了模型大小,加快了速度,但它可改进的空间还很大。再考虑到有斯坦福“官方”加持,它未来一定会更加完善,更加强大。所以,现在正是开始学习使用它的最佳时机——为什么不快人一步,提前掌握这项技能呢?

(本文已投稿给「优达学城」。 原作: Mohd Sanad Zaki Rizvi 编译:欧剃 转载请保留此信息)
编译来源: https://medium.com/analytics-vidhya/introduction-to-stanfordnlp-an-nlp-library-for-53-languages-with-python-code-d7c3efdca118
标签:Udacity、Translate、Python、Machine-Learning