
发表日期:2019-07-11
不是我吓你,在 Python 里用 is 进行比较的后果很危险!
—— 开发:“我这里是好的!”
作者:Brad Dettmer
今天,让我们聊一聊我在 Python 中遇到的一个奇怪的整型数字 bug。我之前在加拿大的 PyCon 2018 上也聊过这个话题,如果你喜欢,可以在这里看到在线 PPT 讲义(英文版),也可以在这里下载PDF版(提取码: mqbx)。
那么,接下来我就详细讲讲这个 bug 背后的原理,帮助大家理解为啥这是一个 bug,以及为啥这个 bug 只在比较数目较大的整型数字时出现。我个人认为,bug 可是初学者最好的老师,希望你们也能有所收获。
让我们开始吧!
起因
预订系统界面截图,右侧是当前可选择的预约时间
事情是这样的。当时我搭建了一个预约试骑动感单车的网站,结果遇到了一个 bug。那时一切看起来都很正常,我甚至已经好几天没有改动系统代码了——所以,当我收到这样一条私信的时候,心里其实是不太相信的:
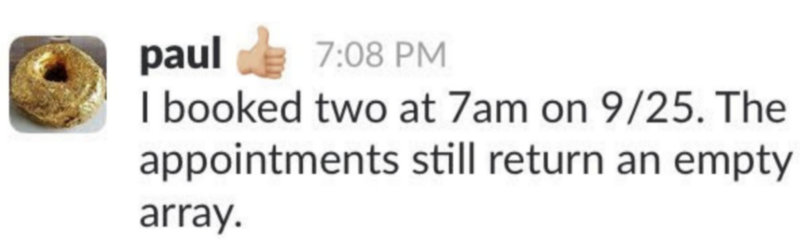
Paul 发给我的私信:“我登记了两个(预约),时间是 9 月 25 日上午 7 点。然而它返回的预约结果总是一个空数组。”
让我们跳过那些“你会用吗”和“可我这是好的”的对话,直接看看这个问题的表现:用户确实提交了两个预约,然而它们并没有被记录到系统里,而且——最让我不可思议的是——在这之前这个功能是好的,这期间我甚至没有改动过代码!这到底什么情况?
经过一番排查,我终于找到了这段没有正常工作的代码,它是在一个循环中,负责根据预约的时间( time_slot )对预约申请进行分组,并返回一个列表给 API 使用:
if appointment.time_slot_id is time_slot.id:
time_slot_appointments.append(appointment)
出问题的地方就是这个 is 啦。但最诡异的是,当 time_slot_id 和 time_slot.id 都是小于等于 256 的整型数字时,这段代码一点问题都没有;只有当预约数量达到一定程度,使得 time_slot_id 或 time_slot.id 大于 256 时,问题就出现了——这个表达式永远返回 False。
这是为什么呢?
两种比较方式的区别
为了解释这个问题,我需要给大家介绍一下 Python 中的两种不同比较方式:
- 使用
is关键字进行的比较是“引用比较”。这里的“引用”就相当于一个索引号,一个地址,或是指向一个对象的指针。用is进行比较正是造成这个奇怪 bug 的根源。 - 使用
==操作符进行的比较是“值比较”,也就是比较两个对象的“值”。
为了直观起见,我要用我最喜欢的狗狗钞票来演示下 is 和 == 这两种比较方式的区别。

Paul 和 Brad 都指向同一张“1 元”狗狗钞票
如上图,Paul 和我共同拥有一张狗狗钞票。如果我们要对彼此的钱进行比较,很明显我们对它的“引用”和“值”都是一样的——我有的这张也正是他拥有的同一张,所以 is 比较的结果是 True;同时,同一张钱的面值肯定一样,所以 == 比较的结果也是 True。
让我们看下一个例子。
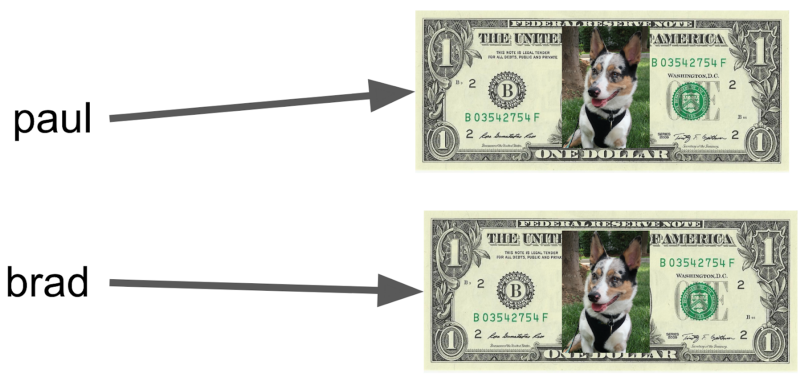
Paul 和 Brad 分别指向一张不同的狗狗钞票,它们的面值都是“1 元”
如上图,我们分别拥有一张自己的狗狗钞票,它们的面值恰好一样。
在这种情况下,如果我们比一比,就会发现,我们的“引用”是不一样的——他的钱并不是我手里的这一张——但“值”是一样的,都是“1 元”。所以 is 比较的结果是 False,== 比较的结果还是 True。
Python 解释器是怎么比较的
想要理解为啥只有数字大到一定程度的时候才会出 bug,让我们回到 Python 解释器里,看看它是怎么管理内存的。
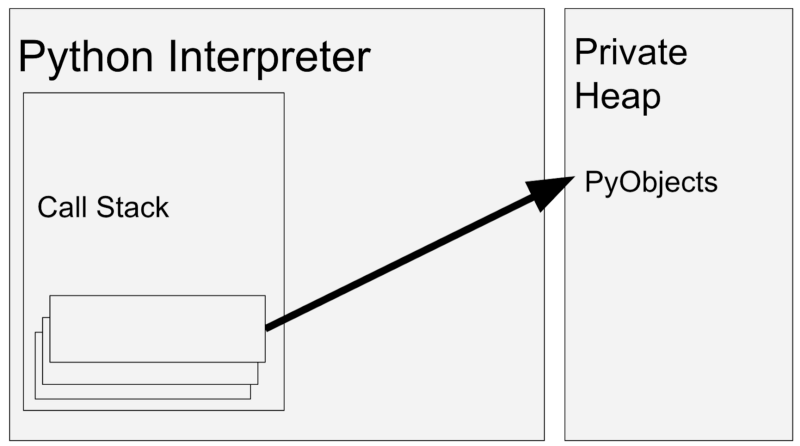
Python 解释器中的调用栈(Call Stack),以及分配的内存中的私有堆(Private Heap)与 PyObject 对象。调用栈中的帧(frame)指向堆中的某个 PyObject 对象。
Python 解释器是一个基于栈的虚拟机,它将所有对象都存储在其私有堆中。你可以把这个“堆”理解成分配好的一段内存,或是一个包含数据的巨大数组。
接着,让我们看看堆里存储的这些对象:

私有堆里存储了一个叫做 small_ints 的数组,包含了从 -5 到 256 的整数
在 Python 中,每一个赋值给变量的值,都作为堆里的一个对象存在。定义这些对象是需要消耗资源的,因为解释器需要调用内存管理来创建/调用/销毁对象。当把一个整数赋值给 Python 中的一个变量时,堆中必须有一个和这个整数对应的 PyObject 对象存在。
在 Python 中,数值型的整型数据是以 PyObject 对象的一个子类型: PyLong 对象的形式存储的。为了减少内存管理在处理小整型数字时候的开销,在 CPython 解释器中使用了“小整数对象池”进行优化。也就是说,值为 -5 到 256 的 PyLong 对象已经预置在 CPython 解释器的私有堆中,可以通过 small_ints 这个数组进行访问。
让我们看一个引用比较(用 is 进行比较)的例子。
首先,我们先初始化一个变量 v 值为整型数字 -5。接着,我们再初始化一个变量 w,值也是 -5。然后,我们用 is 比较这两个对象。结果为 True。如下图所示:
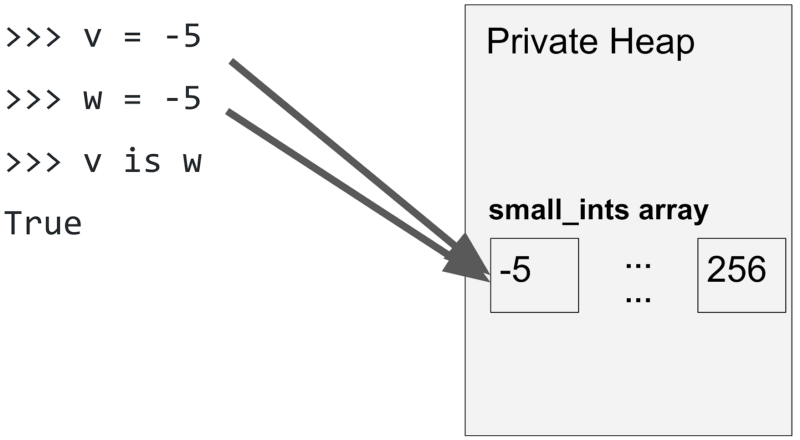
分别给变量 v 和 w 赋值 -5。此时 v 和 w 都指向小整数数组 small_ints 中的 -5,所以 v is w 的结果是 True。
让我们看看 CPython 里的源代码,以便理解一下为什么会出现上面的结果。下面这段代码用于获取一个小整数的对象实例:
get_small_int(sdigit ival)
{
PyObject *v;
...
v = (PyObject *)&small_ints[ival + NSMALLNEGINTS];
...
return v;
}
源代码见: https://github.com/python/cpython/blob/master/Objects/longobject.c#L3005-L3013
如果我们使用的数字很小,解释器会直接从“小整数对象池” small_ints 数组中返回对应的对象。此时,解释器不需要在私有堆里新创建一个 PyObject 对象,因为 small_ints 数组是已经存在的对象。
接下来,我们把 v 和 w 进行比较。
下面这段 CPython 源码将会对两个 PyObject 对象进行比较。换句话说,它比较的是两个地址,或是指针。指针对象其实也是一种变量,它的值是其他变量的地址。运用 C 语言的知识,我们发现,这个比较函数 PyObject_RichCompareBool() 比较的是两个参数的指针(或地址),因为在参数 v 和 w 前面都有一个星号( * )。
/* Perform a rich comparison with integer result.
This wraps PyObject_RichCompare(),
returning -1 for error, 0 for false, 1 for true.
*/
int
PyObject_RichCompareBool(PyObject *v, PyObject *w, int op)
{
...
/* Quick result when objects are the same.
Guarantees that identity implies equality. */
if (v == w) {
if (op == Py_EQ)
return 1;
else if (op == Py_NE)
return 0;
}
...
}
源码见:https://github.com/python/cpython/blob/master/Objects/object.c#L751-L777
顺便一提,CPython 源码里实现引用比较的方式,是用 == 来对比两个对象指针的地址是否相同。换句话说,源码中用值比较的方式来实现引用比较的功能。如果 v 和 w 的对象指针地址相同,那么这个函数返回值为真。所以,如果 v 和 w 是值相同的小整数,它们就都指向 small_ints 数组中的同一个元素,也就会有相同的指针地址,而 PyObject_RichCompareBool() 函数也将返回 True。从更高层面来说,用 is 来对比两个对象,差不多相当于比较私有堆中的两个对象的位置。
那么,如果两个数字并不都在 small_ints 数组里,会怎么样呢?
拿 257 为例,既然 257 并不在 small_ints 数组范围中,当我们初始化 x 和 y 的时候,解释器就会生成两个值都是 257 的 PyObject 对象。那么,当我们用 is 来比较这两个对象的时候,因为它们指向的是不同的对象,表达式的结果就是 False。
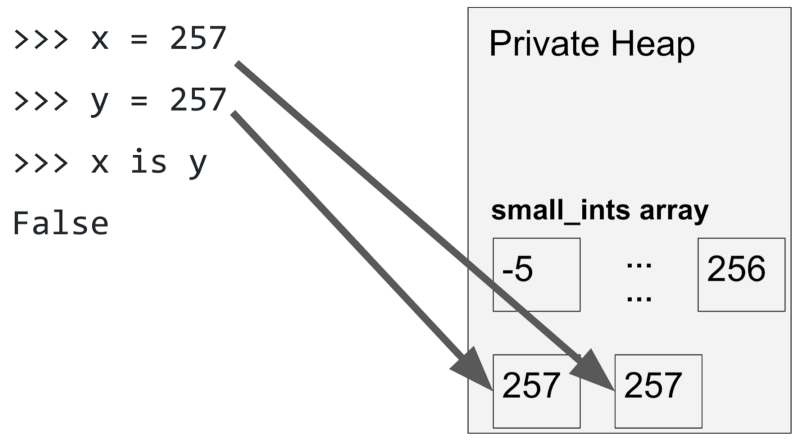
初始化 x 和 y 变量,值都是 257。因为 x 和 y 都不在 small_ints 数组中,所以“ x is y ”的结果是 False
我的代码错在哪里?
现在我们再看看上面的代码。
if appointment.time_slot_id is time_slot.id:
time_slot_appointments.append(appointment)
在这个 if 表达式中,几个对象的相互关系是这样的:
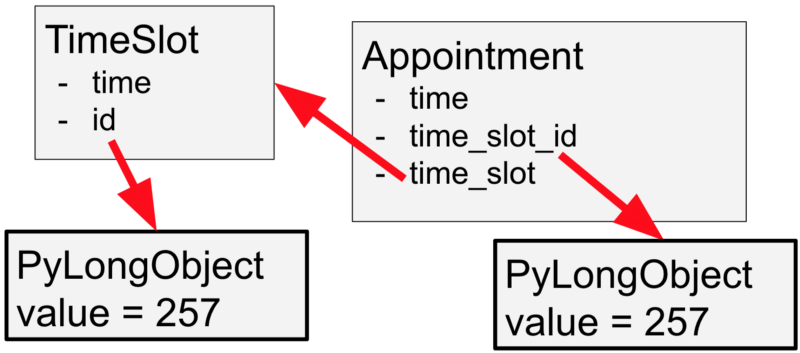
左边是 time_slot 对象,右边是 appointment 对象。对应的 time_slot.id 和 appointment.time_slot_id 都是整数( PyLongObject 对象)。我们可以看到,当值大于 256 的时候,它们指向了不同的对象。
在我的代码中,我用的是引用比较,而不是值比较,这就导致代码会去比较这两个 PyLongObject 对象是否一致——显然它们只是恰好有同样的值——然后就返回了 False 。
那么,这就导致我们在为预约( appointment )查询对应的时间段 ID 时,这个 if 表达式会把所有的预约条目都抛弃掉——因为它找不到返回值为 True 的情况。
要想修复这个 bug,其中一种方式是,把:
if appointment.time_slot_id is time_slot.id:
改成:
if appointment.time_slot.id is time_slot.id:
恩,把一个下划线改成了点。这样一改之后,我们比较的就是同一个 PyLongObject 对象啦。
不明白?没关系,我们看看下图:
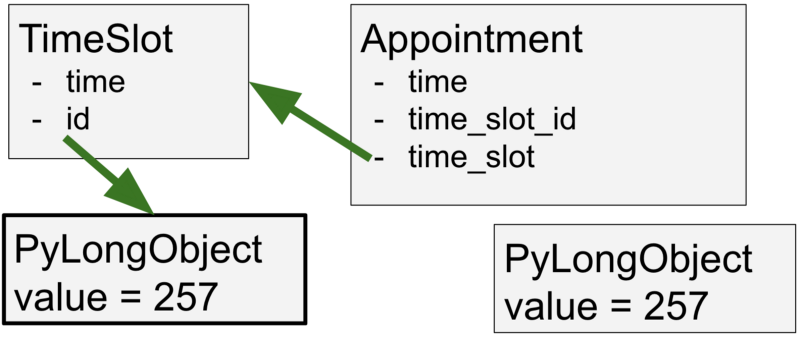
把下划线改成点之后,appointment.time_slot_id 就变成了访问 appointment.time_slot 的 id 属性,而 appointment.time_slot 和 time_slot 是私有堆中的同一个 time_slot 对象。这也就意味着,它们的 id 等属性都是一样的。
用狗狗钞票来类比的话,我们认为 appointment.time_slot 和 time_slot 指向的是同一张钱钱。(突然装可爱)
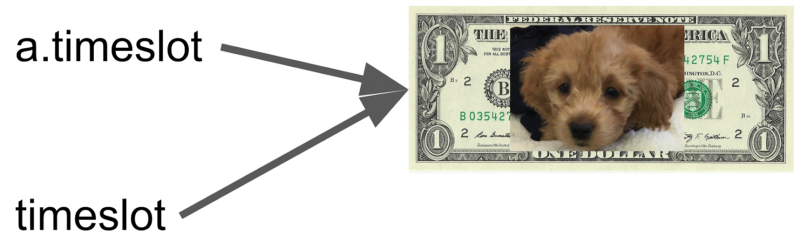
当然,这种修复方式过于投机取巧了,万一程序中出现 time_slot 对象的多个实例,那这个程序又要崩了。
所以,最好的修复方式,还是老老实实用双等号来进行值比较。如果我们一开始就用 == 代替 is 来进行比较,代码就会只注意两个对象的值是否相同,也就不会闹出这样的 bug 啦。
结语
结末的教训是:只有当你十分确定要比较的是两个对象本身的时候,才用 is 进行比较。
此外,当你理解了某个改动为什么能修复某个 bug 的时候,你将更好地理解这门语言的原理。对 Python 来说,一切都是对象,所以用 is 的时候,还是小心为妙。
最后,感谢大家的耐心阅读,也欢迎留言分享你在工作和学习中碰到的奇怪 bug!

(本文已投稿给「优达学城」。 原作: Brad Dettmer ,有删改,编译:欧剃 转载请保留此信息)
编译来源: https://medium.com/peloton-engineering/the-dangers-of-using-is-in-python-f42941124027
标签:Udacity、Translate、Python