
发表日期:2019-07-25
掌握这 5 大神器,在命令行里处理数据科学问题就是小菜一碟
—— 事实证明,能在简单的命令行中完成的工作,远比我原本预想的要多得多,希望它们也能帮上你的忙
作者:Rebecca Vickery
数据科学最让人头疼的地方之一,是你在工作时得不停地切换各种工具。在处理同一项任务的时候,你可能会发现自己不得不同时用 Jupyter Notebook 修改一些代码,在命令行里安装一些新的工具,说不定还得在某个 IDE 里修改一个函数……有的时候,能在同一个软件中完成更多的事情看起来还真不错。

在今天的文章中,我将推荐几个在命令行上进行数据处理的超棒工具。事实证明,能在简单的命令行中完成的工作,远比我原本预想的要多得多,希望它们也能帮上你的忙。
cURL
如果你想要通过许多不同的协议(比如 HTTP/HTTPS/FTP 甚至 Telnet)从各种不同的服务器获取数据,那么 cURL 一定能大显身手。
举个栗子,我们用 cURL 来获取一些公开可用的数据集吧。UCI 机器学习数据库就是一个不错的机器学习数据集来源。
你只需要使用一个简单的 curl 命令,就能从这个网站下载到来自台湾省新竹市捐血中心的数据集。命令语法是 curl [网址],在我们的例子中是:
curl https://archive.ics.uci.edu/ml/machine-learning-databases/blood-transfusion/transfusion.data
在命令行里执行这行命令,将会把获取到的数据内容直接显示在命令行中。
加上一些额外的参数,你就可以把下载到的数据写入某个指定的文件当中。比如下面这行命令,就会在你的当前目录中生成一个 data_dl.csv 文件:
curl -o data_dl.csv https://archive.ics.uci.edu/ml/machine-learning-databases/blood-transfusion/transfusion.data
数据科学项目要获取数据的另外一种常见方式,是通过 API 进行的。cURL 也支持 GET 和 POST 请求,方便你与 API 进行交互。运行以下命令,你将从OpenWeatherMap API中获取一条记录,并保存到名为 weather.json 的 JSON 文件里。
curl -o weather.json -X GET \
'https://api.openweathermap.org/data/2.5/weather?lat=37.3565982&lon=-121.9689848&units=imperial&appid=fd4698c940c6d1da602a70ac34f0b147' \
-H 'Postman-Token: dcf3c17f-ef3f-4711-85e1-c2d928e1ea1a' \
-H 'cache-control: no-cache'
译注:有关 cURL 的详细用法,可以参阅阮一峰老师的这篇文章。
csvkit
csvkit 是一组用于处理 CSV 文件的命令行工具。它可以完成对 CSV 文件进行输入、处理和输出的各种任务。让我们用一个简单的实例来介绍它的功能吧。
首先,我们通过 pip 安装它:
pip install csvkit
在这个例子中,我将用上面那个从 UCI 机器学习数据库里获取的 CSV 文件作为范例。
第一个出场的是 csvclean 命令。它能保证接下来要处理的 CSV 文件格式正确无误。这个命令将自动修复常见的 CSV 错误,并删除任何有问题的行。贴心的是,它默认会输出一个新的清理过的 CSV 文件,而不会覆盖你的原始数据。新文件的文件名始终是 [原文件]_out.csv。如果你确实希望直接覆盖原文件,你可以给命令加上一个 -n 参数。
csvclean data_dl.csv
在这个示例文件中,并没有什么错误存在。但在今后实际处理数据的时候,用这个命令先对文件进行处理,能有效地帮你避免许多问题。
接着,假设我们想要快速检查一下这个文件的内容,我们可以用 csvcut 和 csvgrep 来实现。
比如,用 csvcut 显示所有的列名:
csvcut -n data_dl_out.csv | cut -c6-
Recency (months)
Frequency (times)
Monetary (c.c. blood)
Time (months)
whether he/she donated blood in March 2007
再比如,让我们检查一下 whether he/she donated blood in March 2007 这列中有多少种不同的数据:
csvcut -c "whether he/she donated blood in March 2007" data_dl_out.csv | sed 1d | sort | uniq
0
1
而 csvgrep 命令能让你用正则表达式对 CSV 文件的内容进行筛选,输出过滤后的结果。
让我们使用这个命令来显示所有该列数据为 1 的行:
csvgrep -c "whether he/she donated blood in March 2007" -m 1 data_dl_out.csv
此外,你还能用 csvstat 命令来执行一些简单的数据分析任务:
只需运行 csvstat data_dl_out.csv,就会在命令行中显示出整个文件的描述性统计信息。你也可以增加一个可选的参数,让它只显示某个具体的统计结果:
csvstat --mean data_dl_out.csv
1. a: 373.5
2. Recency (months): 9.507
3. Frequency (times): 5.515
4. Monetary (c.c. blood): 1,378.676
5. Time (months): 34.282
6. whether he/she donated blood in March 2007: None
IPython
使用 IPython,你可以在终端里访问增强的交互式 python 环境。本质上来说,这意味着你可以在命令行里执行 Jupyter Notebook 中可以执行的大部分操作。
你可以按照这些步骤来安装 IPython,不过最简单的方式就是:
pip install ipython
安装完毕之后,在命令行输入 ipython 即可启动 IPython 环境。默认进入的是交互式命令行界面,你可以在这里导入 python 库,也可以在这里进行许多简单的数据分析操作。
让我们对上面那个数据集进行一些简单的分析操作吧。首先,我导入了 pandas 库,然后读取这个 CSV 文件,并检查头几行的数据:
import pandas as pd
data = pd.read_csv('data_dl_out.csv')
data.head()
由于表格的列名实在是太长了,我在 pandas 里给它们进行了一下重命名,并且将处理结果导出到一个新的 CSV 文件中,以便后续处理。
data = data.rename(columns={'Recency (months)': 'recency',
'Frequency (times)': 'frequency',
'Monetary (c.c. blood)': 'volumne',
'Time (months)': 'time',
'whether he/she donated blood in March 2007': 'target'})
data.to_csv('data_clean.csv')
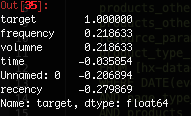
最后,作为练习,让我们使用 pandas 的 corr() 函数,来检查这些特征和目标变量之间的相关性。
corr_matrix = data.corr()
corr_matrix['target'].sort_values(ascending=False)
退出 IPython,只需输入 exit。
csvsql
有时,你可能希望在数据库执行 SQL 查询,以获取所需的数据集。csvsql 命令(其实它包含在 csvkit 内)支持直接在数据库上查询、编写以及创建数据表。它还支持用 SQL 语句对 CSV 文件的内容进行查询。
让我们对上面清理过的数据集运行一个示例查询:
csvsql --query "select frequency, count(*) as rows from data_clean where target = 1 group by frequency order by 2 desc" data_clean.csv
SciKit 机器学习实验室(SciKit-Learn Laboratory,SKLL)
没错,你能在命令行里执行机器学习运算!是的,已经有一些工具也能做到这一点,但 SKLL 可能是其中最易用的一种了。让我们用上面的献血数据库构建一个模型试试。
SKLL 需要在命名一致的目录中放置正确的文件。于是一开始,我们要新建一个名为 train 的文件夹,再把数据文件复制到这个文件夹中,并重命名为 features.csv。
mkdir train
cp data_clean.csv train/features.csv
接着,我们创建一个配置文件,文件名为 predict-donations.cfg,将它放在数据文件夹中。
[General]
experiment_name = Blood_Donations
task = cross_validate
[Input]
train_directory = train
featuresets = [["features.csv"]]
learners = ["RandomForestClassifier", "DecisionTreeClassifier", "SVC", "MultinomialNB"]
label_col = target
[Tuning]
grid_search = false
objective = accuracy
[Output]
log = output
results = output
predictions = output
然后,我们运行命令:
run_experiment -l predict-donations.cfg
不出意外的话,这个机器学习程序将自动开始运行,读取配置文件的内容,创建一个输出文件夹,并把运行结果放在里面。
最后,我们可以用 SQL 查询来分析一下 Blood_Donations_summary.tsv 文件中包含的结果:
cd output
< Blood_Donations_summary.tsv csvsql --query "SELECT learner_name, accuracy FROM stdin "\
> "WHERE fold = 'average' ORDER BY accuracy DESC" | csvlook
结语
那么,以上就是今天介绍的 5 个数据科学方面的实用命令行工具啦。它们都是我在实际工作中接触到的,最容易掌握,也最实用的那些。
在数据科学方面,还有许多非常有用的命令行工具,如果你想真正全面地了解如何在命令行中进行数据科学工作,我个人推荐你阅读《命令行中的数据科学》一书,书中介绍了许多非常实用的命令行工具,以及如何使用它们高效地获取、清洗、探索数据,迅速建立自己的数据分析环境。你也可以在网上免费阅读这本书的英文版全文。

图片来源:豆瓣读书
如果你也有自己中意的命令行工具,也欢迎在下面留言分享!
(本文已投稿给「优达学城」。 原作: Rebecca Vickery ,译者:欧剃 转载请保留此信息)
编译来源: https://towardsdatascience.com/five-command-line-tools-for-data-science-29f04e5b9c16
标签:Udacity、Translate、Python、Data-Science