
发表日期:2019-07-30
单片机中的神器,在机器学习领域也是性价比王者!
—— 先不说了,我这就去买个树莓派 4B!
作者:Alasdair Allan
前不久,树莓派基金会又发布了最新的树莓派(Raspberry Pi)4 代单片机电脑,不但大幅提升了芯片运算能力,可选内存也增加到了最多 4GB,让这张小卡片拥有了类似 PC 级别的性能。而 35~55 美元的超低价格(国内代购的零售价一般在 200 ~ 400 元人民币左右,也算能接受得了啦),让树莓派一直以来都是学校和计算机爱好者手中的“神器”。
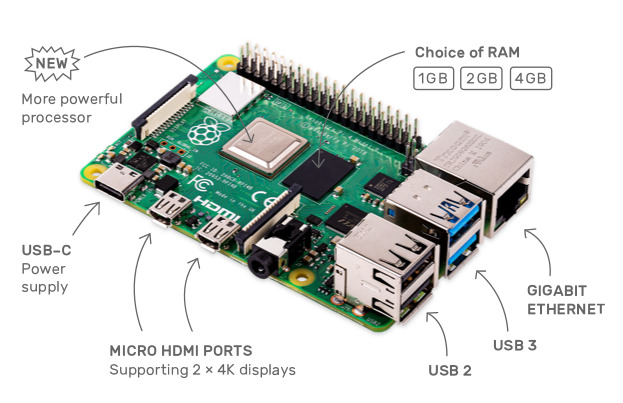
树莓派 4B 的各种接口,图片来源:raspberrypi.org
树莓派 4B 型主要硬件参数如下:
- 1.5GHz 四核 64 位 ARM Cortex-A72 芯片
- LPDDR4 SDRAM 内存,可选 1 / 2 / 4GB
- 板载全双工千兆以太网接口
- 板载双频802.11ac无线网络
- 板载蓝牙5.0
- 两个 USB 3.0 和两个 USB 2.0 接口
- 2 个 micro HDMI 输出,支持同时驱动双显示器,分辨率高达 4K
- VideoCore VI 显示芯片,支持 OpenGL ES 3.x.
- 支持 HEVC 视频 4Kp60 硬解码
- USB Type-C 供电接口
不仅如此,最近还有大佬成功在树莓派 4 上跑起了 TensorFlow,搞了一把机器学习模型的性能评测,真的这么神吗!
让我们一起看看吧!
太长不看版
-
用上了最新的 TensorFlow Lite 之后,跑同一个数据集的速度达到了之前用 TensorFlow 时的 3 至 4 倍。
-
树莓派 4B 处理机器学习任务的算力超过树莓派 3B+ 的4倍,已经能和 NVIDIA Jetson Nano 有的一拼了。
-
如果加上 Coral USB 加速器的话,处理速度甚至能比肩 Google 的 Coral 开发板,而总价格还更便宜。
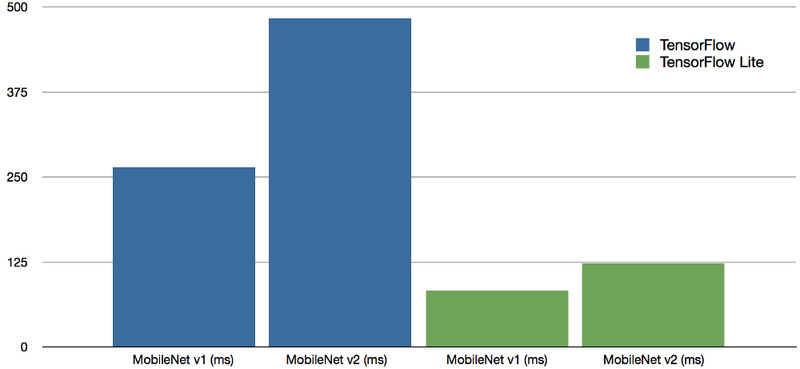
新树莓派 4b 的机器学习任务跑分结果。单位:毫秒
本次测试中在新树莓派 4b 上分别使用 MobileNet v1 SSD 0.75 深度模型,以及 MobileNet v2 SSD 模型进行基准测试,都使用了 Common Objects in Context (COCO) 数据集进行训练,输入图像分辨率都是 300x300,使用 TensorFlow 时运算时间分别为 263.9 毫秒和 483.5 毫秒,而使用 TensorFlow Lite 时的运算时间为 82.7 毫秒和 122.6 毫秒。图片来源:hackster.io
第一部分 跑分测试细节
设备、模型和数据集
我们在树莓派 3b+、树莓派 4B(4G内存版)以及一些其他设备上都进行了测试,测试的模型均为 MobileNet v2 SSD 以及 MobileNet v1 0.75 深度 SSD 模型,且都使用 COCO 数据集进行了训练。
我们使用的其他设备包括 Coral 开发板、NVIDIA Jetson Nano,分别加挂了 Coral USB 加速器、初代 Movidus 神经网络计算棒、二代英特尔神经网络计算棒的树莓派,以及一台 MacBook Pro。此外,我们还加入了在树莓派上运行 Xnor.ai 的 AI2GO 平台,使用的是 Xnor 的私有卷积网络程序。
ℹ️ 附注:树莓派 3B+ 型没有 USB 3 接口,所以无法使用 USB 3 版本的 Coral USB 加速器。由于 Intel OpenVINO 不支持 Python 3.7,所以初代 Movidus 神经网络计算棒和二代英特尔神经网络计算棒在树莓派 4 上还无法正常工作。但随着新设备的普及,近期内官方可能就会推出针对树莓派 4 的适配了。
在纯靠树莓派算力的测试中,我们还进行了 TensorFlow 和 TensorFlow Lite(模型经过转换)的对比测试。
机器学习任务方面,我准备了一张分辨率为 3888x2916 的待识别图片,图片中包含两个可识别的对象:一个香蕉🍌,一个苹果🍎。在喂给模型之前,图片将会被缩小到 300x300 像素,每个模型将会执行一万次,抛弃第一次的处理结果(可能存在因为载入瓶颈造成的延迟),将剩下的处理结果取平均速度。

程序要识别的就是这样张图,图片来源:hackster.io
详细数据
让我们先看一下每个设备上的详细运行数据:
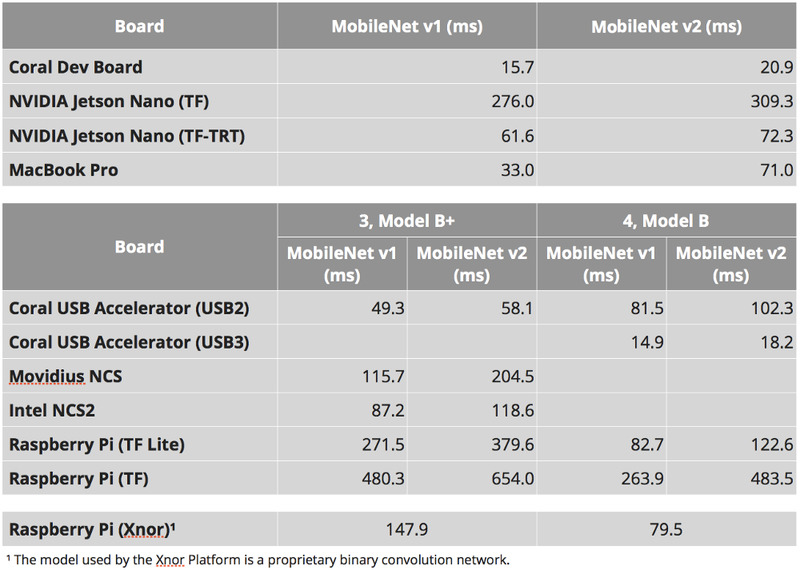
测试结果,单位:毫秒。其中在 Xnor.ai 的 AI2GO 平台上运行的程序使用的是他们私有的卷积网络程序模型,因此没有区分 MobileNet v1 和 v2。图片来源:hackster.io
⚠️ 注意:根据我们之前对树莓派 4 的评测结果,你需要在板子上添加一个由树莓派 GPIO 口驱动的散热风扇,以便保持 CPU 的温度稳定,避免因为高温造成 CPU 保护性降速。
一开始,在 TensorFlow 测试中,我们发现树莓派 4 的处理速度比上代提升了大约一倍,这差不多算是因为新的 ARM Cortex-A72 处理器对 NEON 指令集的处理容量比上代多了将近一倍。也就是说,如果能用上效率更高的 NEON 内核代码,这个速度还有提升的空间。
接着,我们发现在使用 TensorFlow Lite 的时候,整体速度有了相当显著的提升,总速度达到了 TensorFlow 测试的 3~4 倍。有趣的是,在树莓派 3 上,TensorFlow Lite 的提升则相对有限,只能达到原来的 2 倍上下。
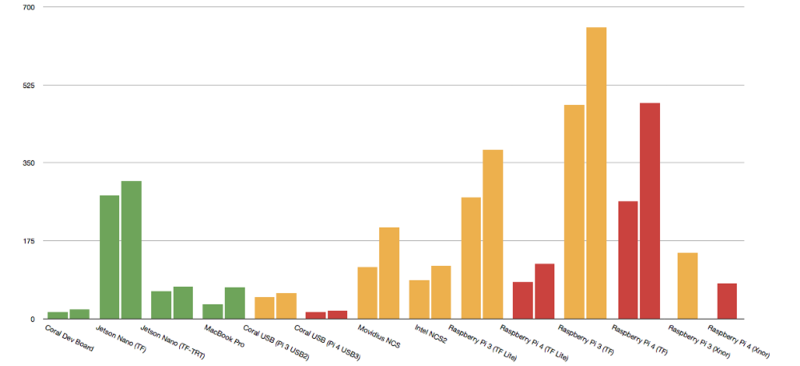
各设备运算时间横向对比。单位:毫秒。图片来源:hackster.io
上图是各设备运算时间的横向对比。每一个设备有两组数据,左侧的是用 MobileNet v1 SSD 0.75 深度模型,右侧的是 MobileNet v2 SSD 模型。Xnor AI2GO 平台的两个设备(树莓派3/4)都只使用 Xnor 私有的权重模型。Raspberry Pi 3B+ 的所有测试结果均以黄色显示,Raspberry Pi 4B 上的测试结果以红色显示。其他不依赖于 Raspberry Pi 的独立平台以绿色显示。
拜 TensorFlow Lite 所赐,树莓派 4 的运算时间已经减少到能正面刚 NVIDIA Jetson Nano 和英特尔 Movidius 系列硬件的程度了。
⚠️ 注意:Movidius 神经网络计算棒和英特尔神经网络计算棒 2 代因为树莓派 3 没有 USB 3 的接口,所以只能在 USB 2 下工作,所以速度受到了一定的限制。然而,目前这两个设备无法在树莓派 4 上正常工作,所以对应的测试无法进行。也许这要等 OpenVINO 框架支持 Python 3.7 之后了吧。
如果你曾经准备购买 NVIDIA Jetson Nano 来进行机器学习工作,我个人觉得你不妨看看价格只有它一半的树莓派 4 😊。
结果汇总
新树莓派 4 带来的新能提升,使得树莓派成为了相当有竞争力的前沿机器学习处理平台。在用上 TensorFlow Lite 技术之后,树莓派 4 的处理能力得到了巨大的提升,能和专业的 NVIDIA Jetson Nano 以及英特尔神经网络计算棒 2 代一较高下。
新的树莓派 4 比 上述两种设备都便宜得多,1GB 版本的售价为 35 美元,4GB 版本的售价为 55 美元,而 NVIDIA Jetson Nano 和英特尔神经网络计算棒 2 代每个的售价都要 99 美元。特别是,对于计算棒来说,你还得买个树莓派来跟它配合使用,所以总成本将达到 134 美元。
虽然目前 Google 的 Coral 开发板依旧是同类产品中算力最强的板子,但既然有了 USB 3 加持,树莓派 4 + Coral USB 加速器的组合,价格也不过就在 109.99 美元上下,比起单价 149 美元的 Coral 开发板还是便宜了 39.01 美元,而且在性能方面甚至还略微超过了 Coral 开发板。
第二部分 测试方法与代码
在树莓派上安装 TensorFlow Lite
过去,在树莓派上安装 TensorFlow 是一个艰难的过程,但从去年下半年以来,整个过程简单了不少。幸运的是,在社区的帮助下,现在安装 TensorFlow Lite 相比之下可是轻松多了。你甚至都不需要从源代码来重新编译。

树莓派 4B,图片来源:raspberrypi.org
首先,你需要下载最新的 Raspbian Lite,并安装设置你的树莓派。除非你已经准备好了有线网络,或是有显示器/键盘,否则你需要至少设置好无线网络连接和SSH。
准备好设备之后,你需要在电脑上打开一个命令行窗口,SSH 连接到你的树莓派上:
% ssh pi@raspberrypi.local
幸运的是,虽然官方的 TensorFlow 二进制发行版不包含 TensorFlow Lite ,但是有一个第三方的 TensorFlow Lite 发行版,这意味着我们不需要从源代码进行编译和安装。
当你 SSH 登录到树莓派之后,在安装 TensorFlow Lite 之前,你需要先更新软件包,安装基础的编译工具:
$ sudo apt-get update
$ sudo apt-get install build-essential
$ sudo apt-get install git
ℹ️ 附注:如果你是在现有的系统上进行安装,且你已经安装了官方版的 TensorFlow,你需要先将其删除才能进行下一步。删除的命令是
sudo pip3 uninstall tensorflow。
虽然目前还没有专门针对 Python 3.7 构建的 TensorFlow Lite,但我们可以使用一个基于 Python 3.5 的版本。只不过在安装之前,需要进行一些调整:
$ sudo apt-get install libatlas-base-dev
$ sudo apt-get install python3-pip
$ git clone https://github.com/PINTO0309/Tensorflow-bin.git
$ cd Tensorflow-bin
$ mv tensorflow-1.14.0-cp35-cp35m-linux_armv7l.whl tensorflow-1.14.0-cp37-cp37m-linux_armv7l.whl
$ pip3 install --upgrade setuptools
$ pip3 install tensorflow-1.14.0-cp37-cp37m-linux_armv7l.whl
安装过程需要耗费一些时间。你可以放松一下,喝杯咖啡什么的,等安装完毕了再回来看看。一旦安装完毕之后,你可以用下面的代码进行简单的测试,看看安装是否正确:
$ python3 -c "import tensorflow as tf; tf.enable_eager_execution(); print(tf.reduce_sum(tf.random_normal([1000, 1000])))"
⚠️ 注意:当你
import tensorflow的时候,可能会出现一些运行时警告(Runtime Warning),你可以不用管它,因为那基本上只是提示你这个库是在 Python 3.5 上编译的,当前运行的环境是 Python 3.7。
那么,你现在应该已经安装好了 TensorFlow Lite,接下来需要安装 OpenCV 库、Python 图像处理库(PIL)的一个分支 Pillow,以及 NumPy:
$ sudo apt-get install python3-opencv
$ pip3 install Pillow
$ pip3 install numpy
上面这些安装成功完成之后,你就可以试试下载运行我们的测试代码了。
测试代码及资料下载
测试代码、模型总计约 425M,译者搬运在百度网盘:
链接: https://pan.baidu.com/s/1DzUpkF89bYGccMXExXJMNQ 提取码: e7fr
结语
总的来说,要在相对平等的基础上对这些机器学习设备进行横向比较还是比较难的。但有一点是明显的,树莓派 4 确实是个不错的机器学习平台。
那么,你是否有打算用树莓派 4 的机器学习能力做点什么新奇的玩意呢?欢迎留言分享!
(本文已投稿给「优达学城」。 原作: Alasdair Allan ,译者:欧剃 转载请保留此信息)
编译来源: https://blog.hackster.io/benchmarking-tensorflow-lite-on-the-new-raspberry-pi-4-model-b-3fd859d05b98
标签:Udacity、Translate、Python、Machine-Learning