
发表日期:2020-01-07
新世纪数据可视化指南
—— 你离全交互式图表就差这么一行代码!
作者:Will Koehrsen

图片来源:pexels.com
“沉没成本谬误”是人们常犯的几种认知偏差之一。它指的是人们倾向于继续把时间和金钱投入一件已经注定要失败的事情,只因为他们在这件事上已经投入了(“沉没”)太多的成本。沉没成本谬误同样适用于在不好的职位上待了比正常更长的时间,在一个明显不可能的项目上埋头苦干,以及(你猜的没错)继续用一个陈旧、枯燥的绘图库——matplotlib——即使当更高效、更美观、可互动性更好的替代品已经出现的时候。
在过去的几个月里,我意识到我还守着 matplotlib 的唯一原因,不过就是因为我已经“沉没”在里面的几百个小时的时间成本——这都是为了学会它那复杂的语法。这也导致我花费了不知多少个深夜,在 StackOverflow 上搜索如何格式化日期或增加第二个Y轴。幸运的是,随着数据分析技术的不断进步和开源软件的不断发展,如今我们有了更多更好的选择。纵观这些选项,很容易就能发现一款易于使用、文档健全、功能强大的开源 Python 绘图库—— Plotly。在今天的文章里,请跟我们一起深入体验 plotly,了解它如何用超简单的(甚至只要一行!)代码,绘制出更棒的图表。
本文中所有代码都已经在 Github 上开源,所有的图表都是可交互的,请使用NBViewer查看 。 Github 源代码地址: https://github.com/WillKoehrsen/Data-Analysis/blob/master/plotly/Plotly%20Whirlwind%20Introduction.ipynb
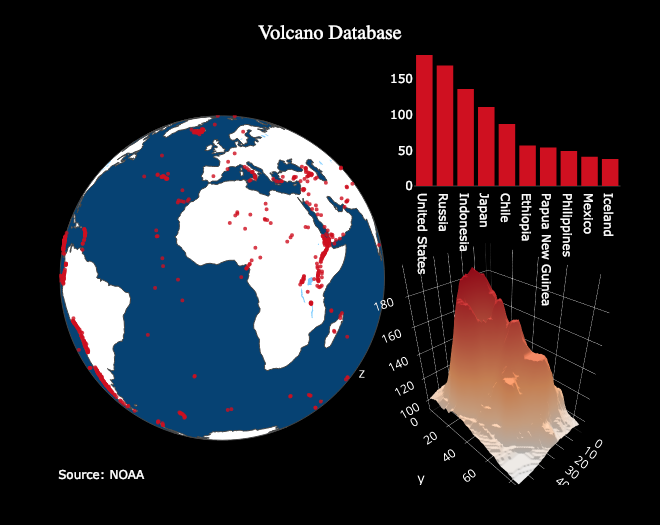
plotly 绘制的范例图表。图片来源:plot.ly
Plotly 概述
plotly 的 Python 软件包是一个开源的代码库,它基于 plot.js,而后者基于 d3.js。我们实际使用的则是一个对 plotly 进行封装的库,名叫 cufflinks,它能让你更方便地使用 plotly 和 Pandas 数据表协同工作。
(注:Plotly 本身是一个拥有多个不同产品和开源工具集的可视化技术公司。Plotly 的 Python 库是可以免费使用的,在离线模式可以创建数量不限的图表,在线模式因为用到了 Plotly 的共享服务,只能生成并分享 25 张图表。)
本文中的所有可视化图表都是在 Jupyter Notebook 中使用离线模式的 plotly + cufflinks 库完成的。在使用 pip install cufflinks plotly 完成安装后,你可以用下面这样的代码在 Jupyter 里完成导入:
# 导入 plotly 库
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import iplot, init_notebook_mode
# 在离线模式使用 plotly + cufflinks 库
import cufflinks
cufflinks.go_offline(connected=True)
init_notebook_mode(connected=True)
单变量分布:柱状图和箱形图
单变量分析图往往是开始数据分析时的标准做法,而柱状图基本上算是单变量分布分析时必备的图表之一(虽然它还有一些不足)。
就拿我的博客文章点赞总数为例(原始数据见 Github:https://github.com/WillKoehrsen/Data-Analysis/tree/master/medium ),让我们做一个简单的交互式柱状图(代码中的 df 是标准的 Pandas dataframe 对象):
df['claps'].iplot(kind='hist',
xTitle='claps',
yTitle='count',
title='Claps Distribution')
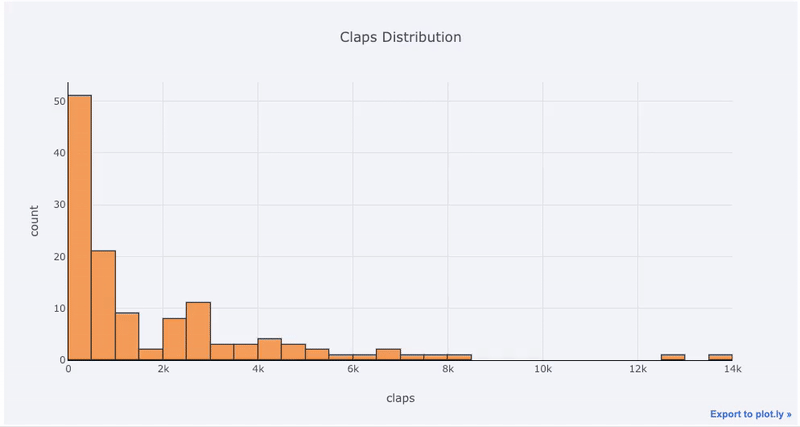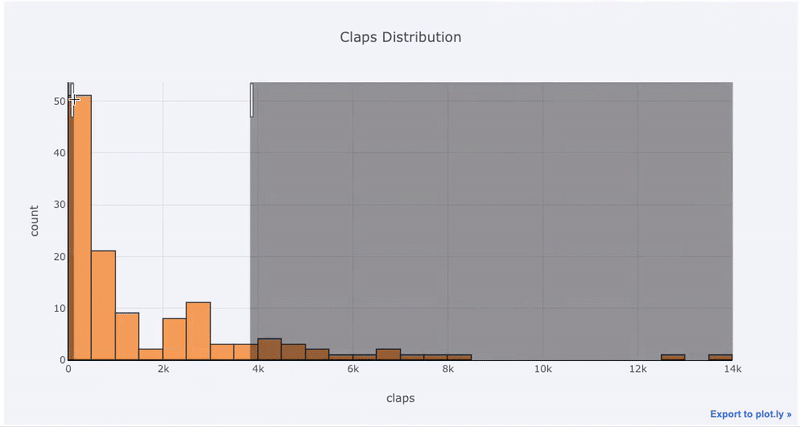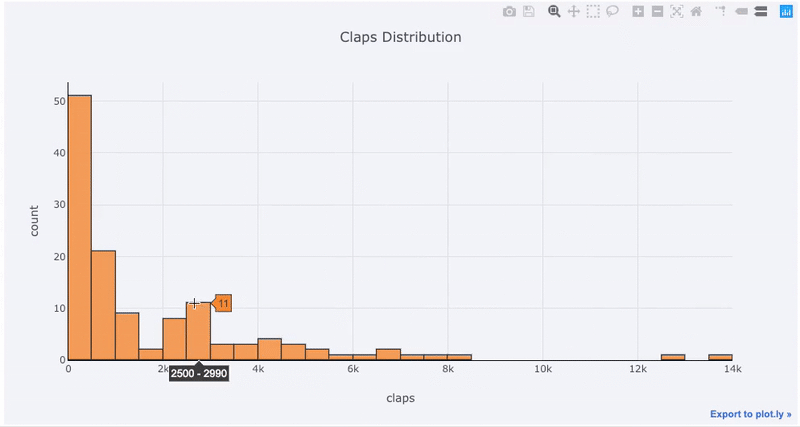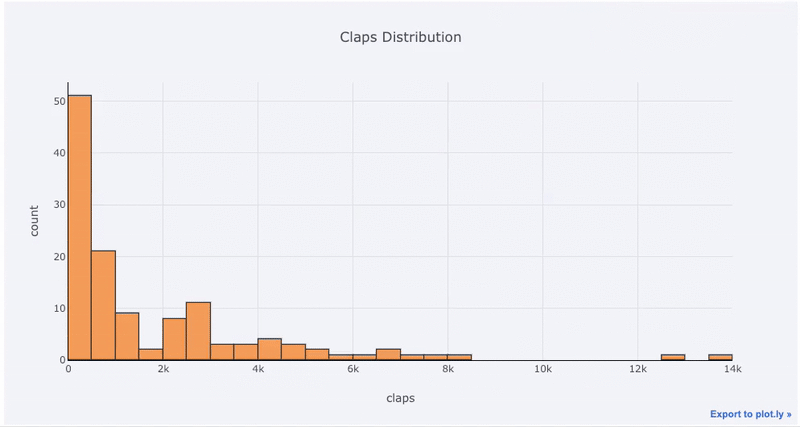
使用 plotly+cufflinks 创建的交互式柱状图
对于已经习惯 matplotlib 的同学,你们只需要多打一个字母(把 .plot 改成 .iplot ),就能获得看起来更加美观的交互式图表!点击图片上的元素就能显示出详细信息、随意缩放,还带有(我们接下来会提到的)高亮筛选某些部分等超棒功能。
如果你想绘制堆叠柱状图,也只需要这样:
df[['time_started', 'time_published']].iplot(
kind='hist',
histnorm='percent',
barmode='overlay',
xTitle='Time of Day',
yTitle='(%) of Articles',
title='Time Started and Time Published')
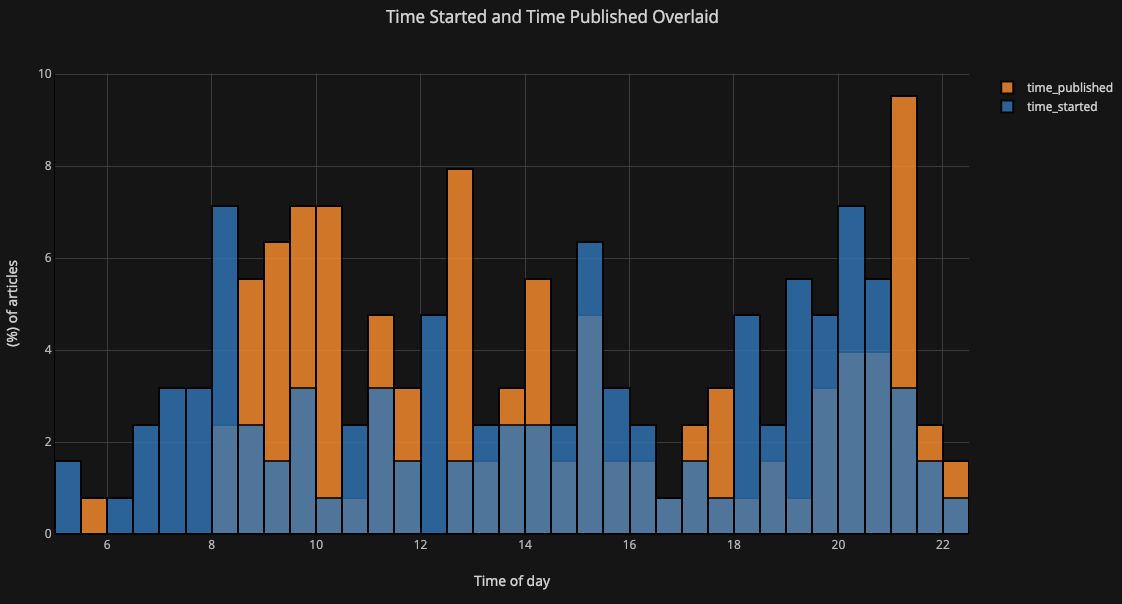
运行结果
对 pandas 数据表进行简单的处理,并生成条形图:
# 按照月份进行重采样,再绘图
df2 = df[['view','reads','published_date']].\
set_index('published_date').\
resample('M').mean()
df2.iplot(kind='bar', xTitle='Date', yTitle='Average',
title='Monthly Average Views and Reads')
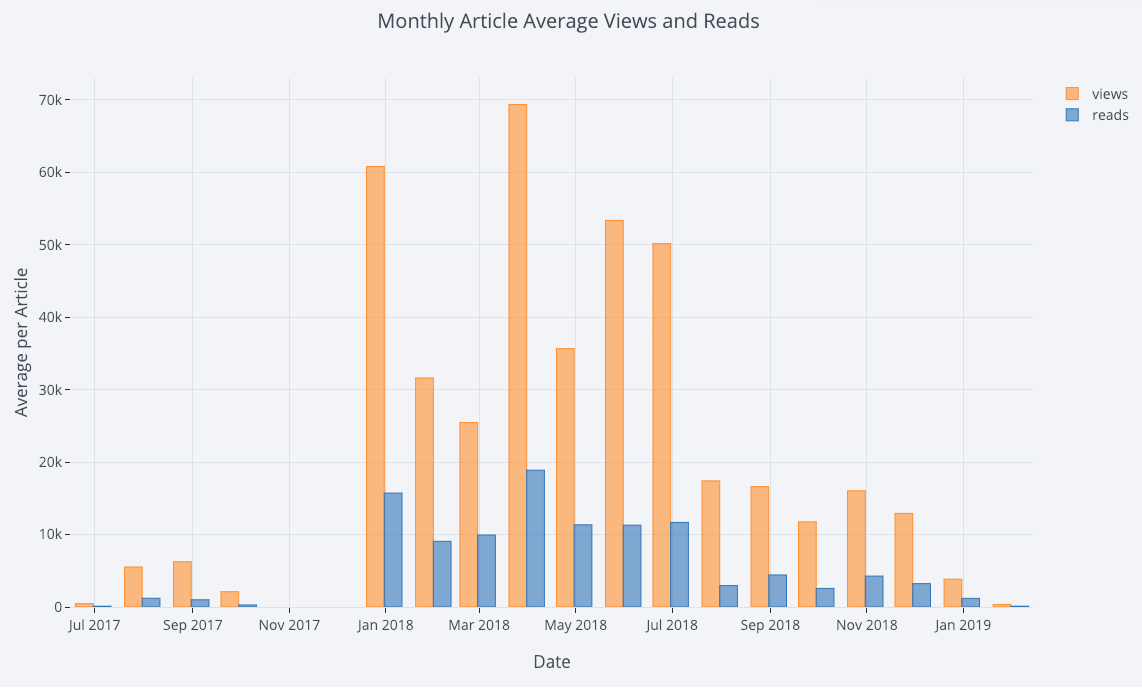
运行结果
就像上面展示的那样,我们可以将 plotly + cufflinks 和 pandas 的能力整合在一起。比如,我们可以先用 .pivot() 进行数据透视表分析,然后再生成条形图。
比如统计不同发表渠道中,每篇文章带来的新增粉丝数:
df.pivot(columns='publication', values='fans').iplot(
kind='box',
yTitle='fans',
title='Fans Distribution by Publication')
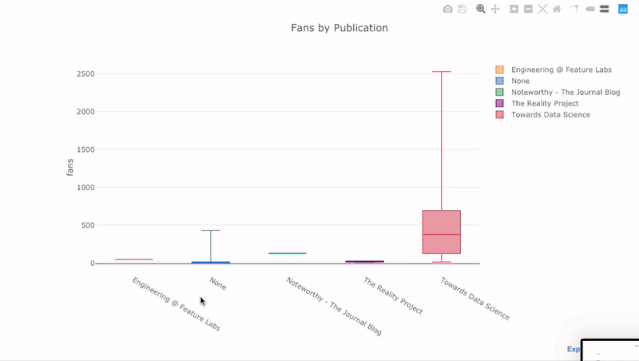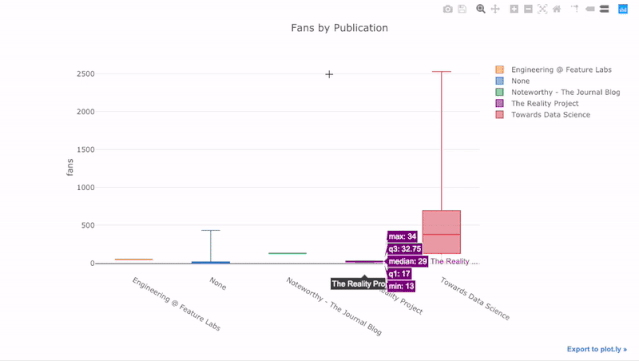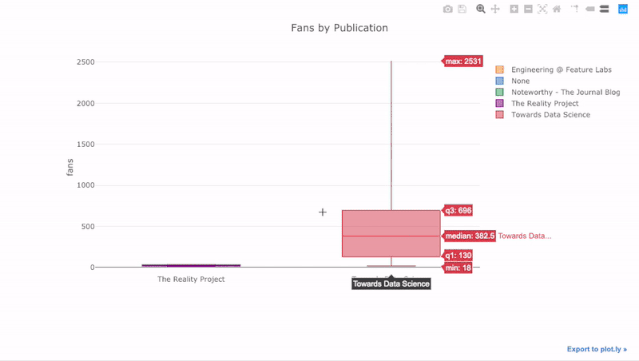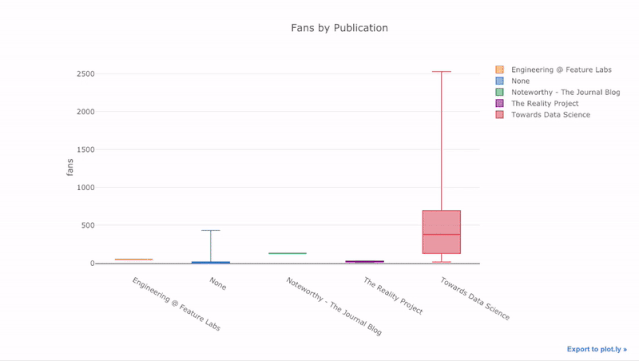
运行结果
交互式图表带来的好处是,我们可以随意探索数据、拆分子项进行分析。箱型图能提供大量的信息,但如果你看不到具体数值,你很可能会错过其中的一大部分!
散点图
散点图是大多数分析的核心内容,它能让我们看出一个变量随着时间推移的变化情况,或是两个(或多个)变量之间的关系变化情况。
时间序列分析
在现实世界中,相当部分的数据都带有时间元素。幸运的是,plotly + cufflinks 天生就带有支持时间序列可视化分析的功能。
以我在“Towards Data Science”网站上发表的文章数据为例,让我们以发布时间为索引构建一个数据集,看看文章热度的变化情况:
# 构建一个包含 Towards Data Science 上的文章数据的数据集
tds = df[df['publication'] == 'Towards Data Science'].\
set_index('published_date')
# 将读取的时间绘制为时间序列图形
tds[['fans', 'word_count', 'title']].iplot(
y='fans',
mode='lines+markers',
secondary_y = 'word_count',
secondary_y_title='Word Count',
opacity=0.8,
size=8,
symbol=1,
xTitle='Date',
yTitle='Claps',
text='title',
title='Fans and Word Count over Time')
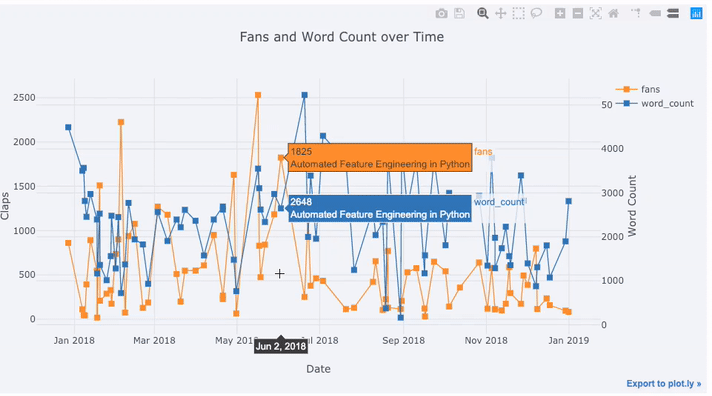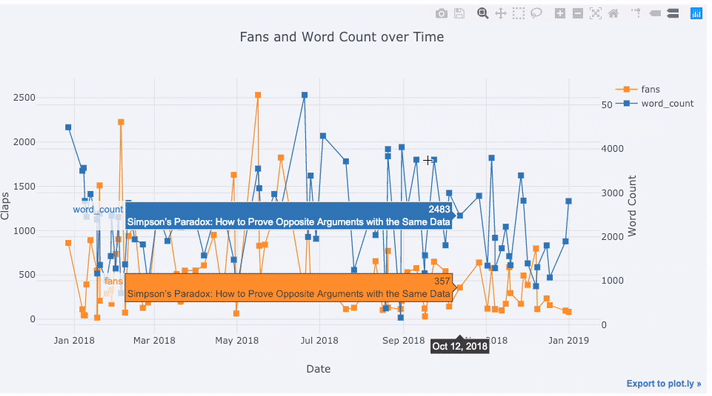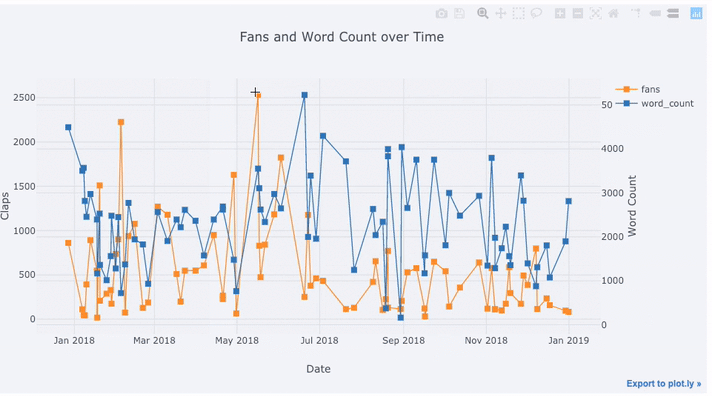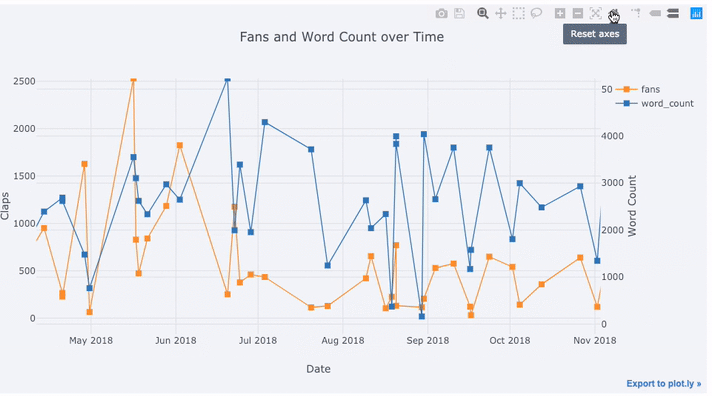
运行结果
在上图中,我们用一行代码完成了几件事情:
- 自动生成美观的时间序列 X 轴
- 增加第二条 Y 轴,因为两个变量的范围并不一致
- 把文章标题放在鼠标悬停时显示的标签中
为了显示更多数据,我们可以方便地添加文本注释:
tds_monthly_totals.iplot(
mode='lines+markers+text',
text=text,
y='word_count',
opacity=0.8,
xTitle='Date',
yTitle='Word Count',
title='Total Word Count by Month')
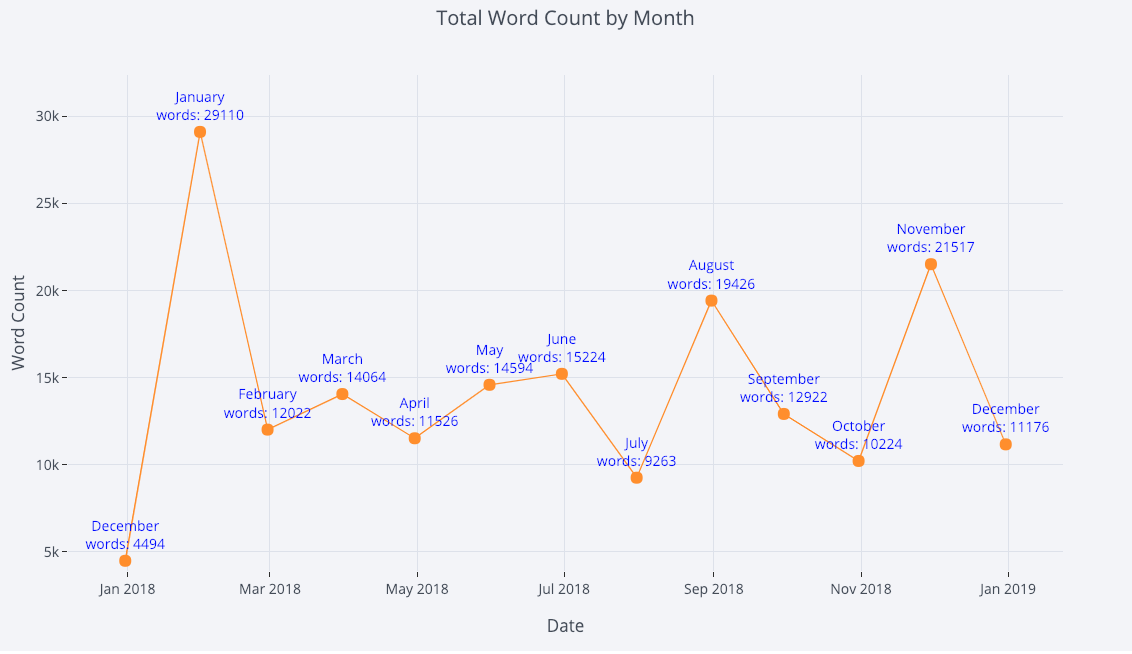
带有文本注释的散点图
下面的代码中,我们将一个双变量散点图按第三个分类变量进行着色:
df.iplot(
x='read_time',
y='read_ratio',
# 指定分类变量
categories='publication',
xTitle='Read Time',
yTitle='Reading Percent',
title='Reading Percent vs Read Ratio by Publication')
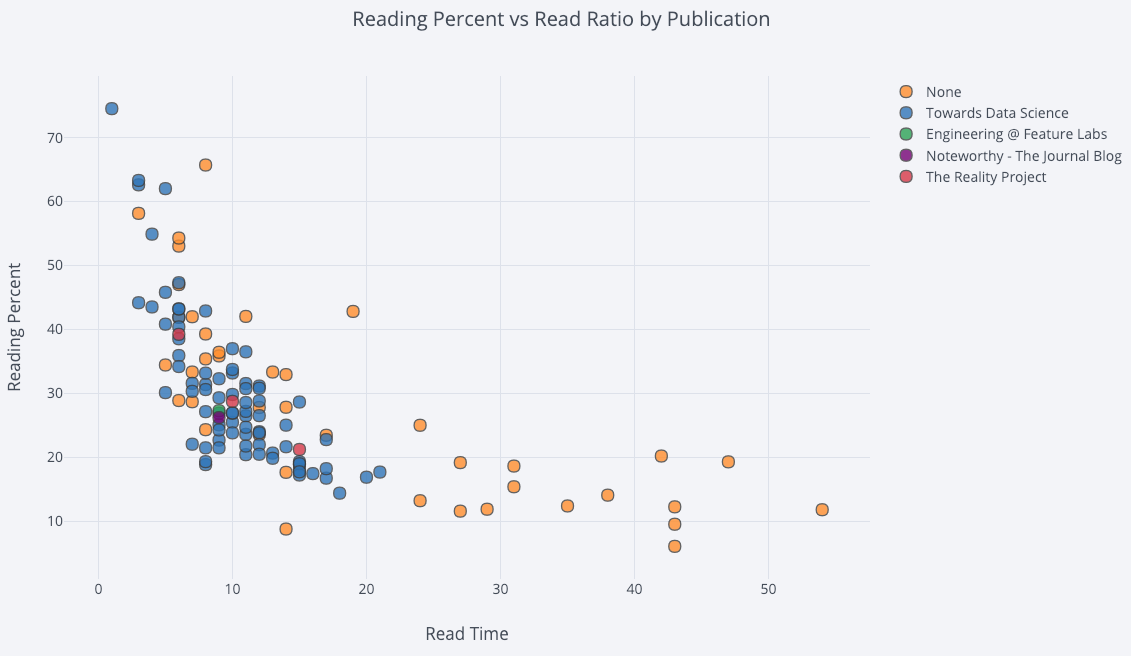
运行结果
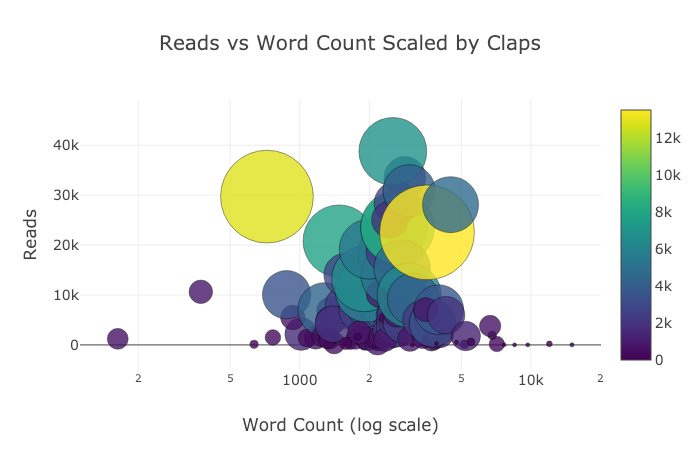
接下来我们要玩点复杂的:对数坐标轴。我们通过指定 plotly 的布局(layout)参数来实现这一点(关于不同的布局,请参考官方文档 https://plot.ly/python/reference/ ),同时我们把点的尺寸(size参数)和一个数值变量 read_ratio (阅读比例)绑定,数字悦达,泡泡的尺寸也越大。
tds.iplot(
x='word_count',
y='reads',
size='read_ratio',
text=text,
mode='markers',
# 对数坐标轴
layout=dict(
xaxis=dict(type='log', title='Word Count'),
yaxis=dict(title='Reads'),
title='Reads vs Log Word Count Sized by Read Ratio'))
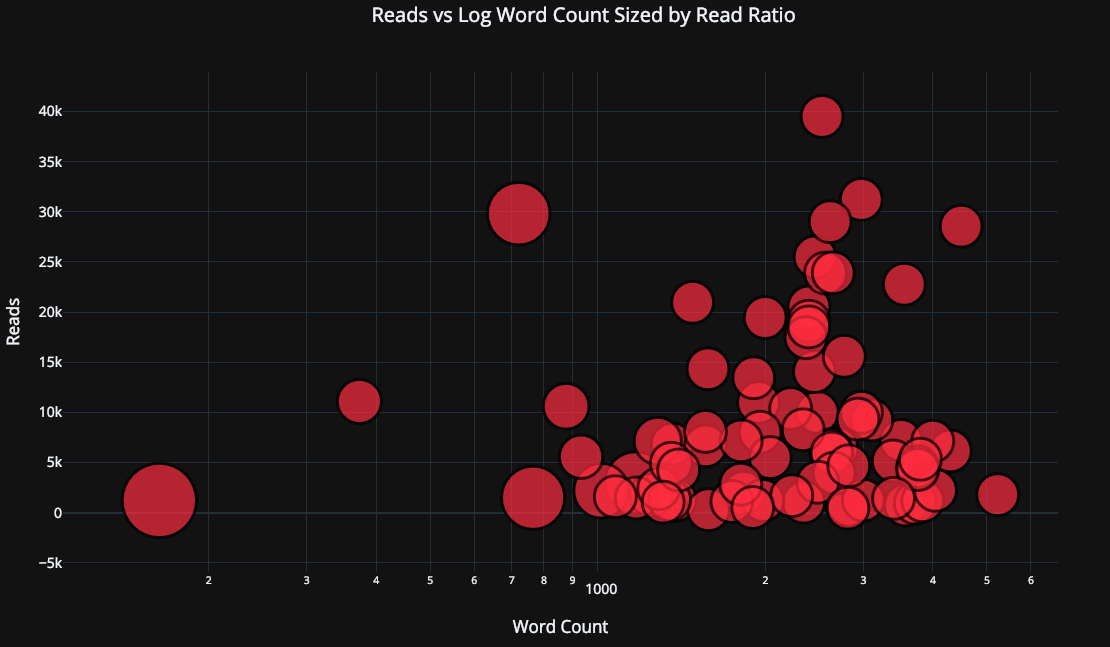
运行结果
如果想要更复杂一些(详见我放在 Github 的源代码),我们甚至可以在一张图里塞进 4 个变量!(然而并不推荐你们真的这么搞)
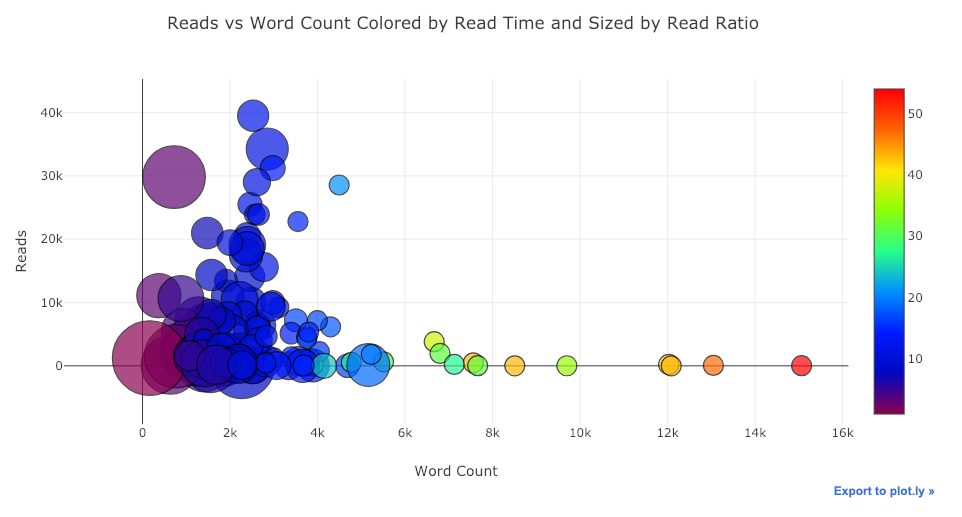
看着是很酷炫
和前面一样,我们可以将 pandas 和 plotly+cufflinks 结合起来,实现许多有用的图表:
df.pivot_table(
values='views',
index='published_date',
columns='publication').cumsum().iplot(
mode='markers+lines',
size=8,
symbol=[1, 2, 3, 4, 5],
layout=dict(
xaxis=dict(title='Date'),
yaxis=dict(type='log', title='Total Views'),
title='Total Views over Time by Publication'))
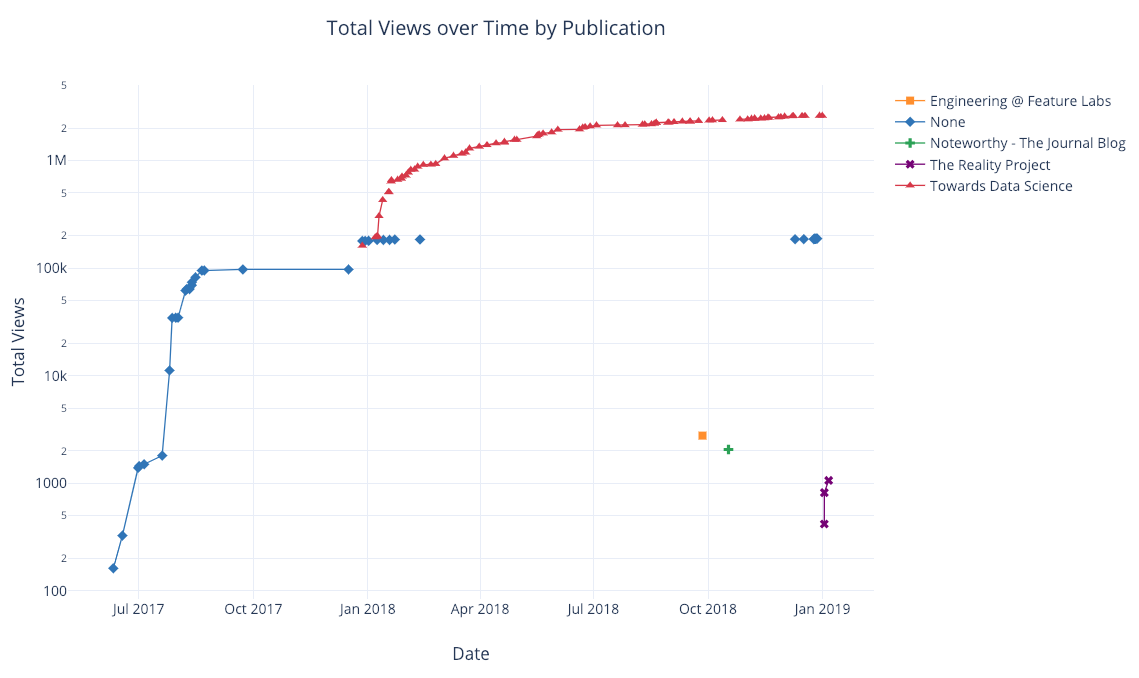
建议你查看官方文档,或者我的源代码,里面有更多的范例和函数实例。只需要简单的一两行代码,就可以为你的图表加上文字注释,辅助线,最佳拟合线等有用的元素,并且保持原有的各种交互式功能。
高级绘图功能
接下来,我们要详细介绍几种特殊的图表,平时你可能并不会很经常用到它们,但我保证只要你用好了它们,一定能让人刮目相看。我们要用到 plotly 的 figure_factory 模块,只需要一行代码,就能生成超棒的图表!
散点图矩阵
假如我们要探索许多不同变量之间的关系,散点图矩阵(也被称为SPLOM)就是个很棒的选择:
import plotly.figure_factory as ff
figure = ff.create_scatterplotmatrix(
df[['claps', 'publication', 'views',
'read_ratio','word_count']],
diag='histogram',
index='publication')
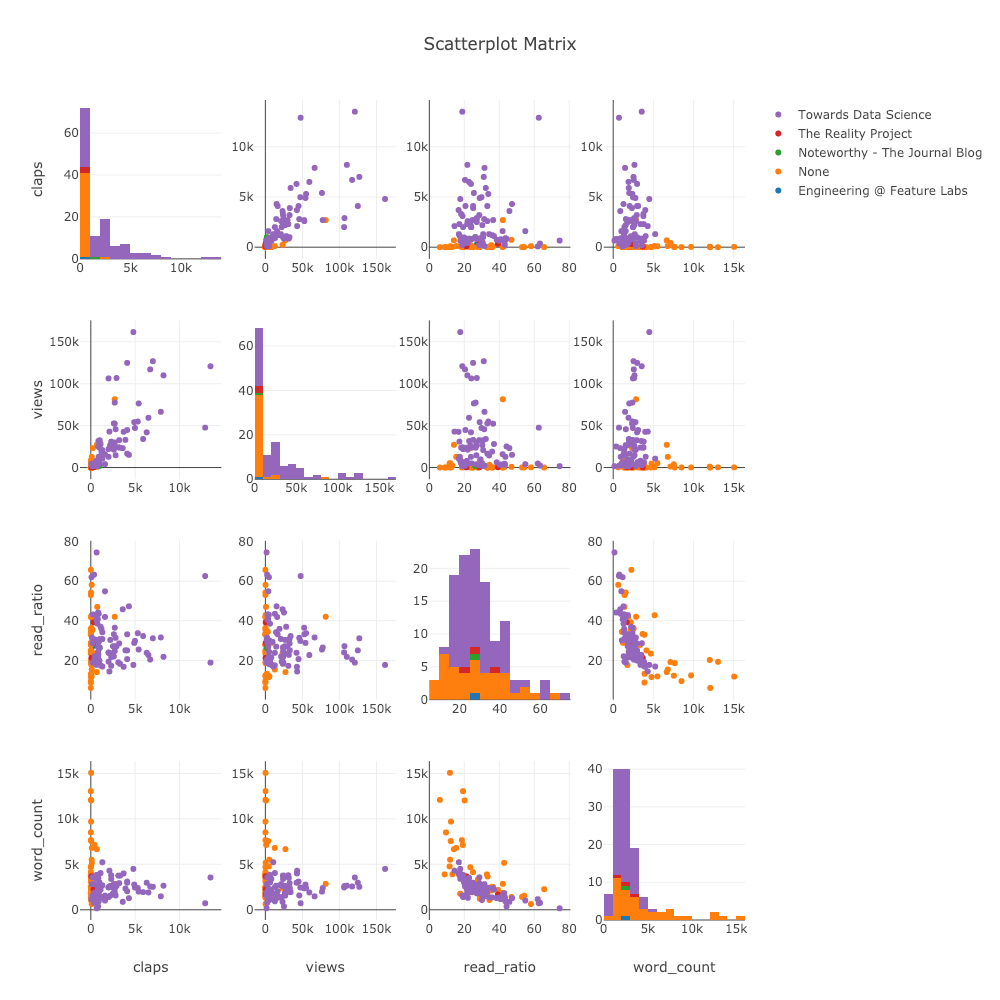
交互式 SPLOM
即使是这样复杂的图形,也是完全可交互的,让我们能更详尽地对数据进行探索。
关系热图
为了体现多个数值变量间的关系,我们可以计算它们的相关性,然后用带标注热度图的形式进行可视化:
corrs = df.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
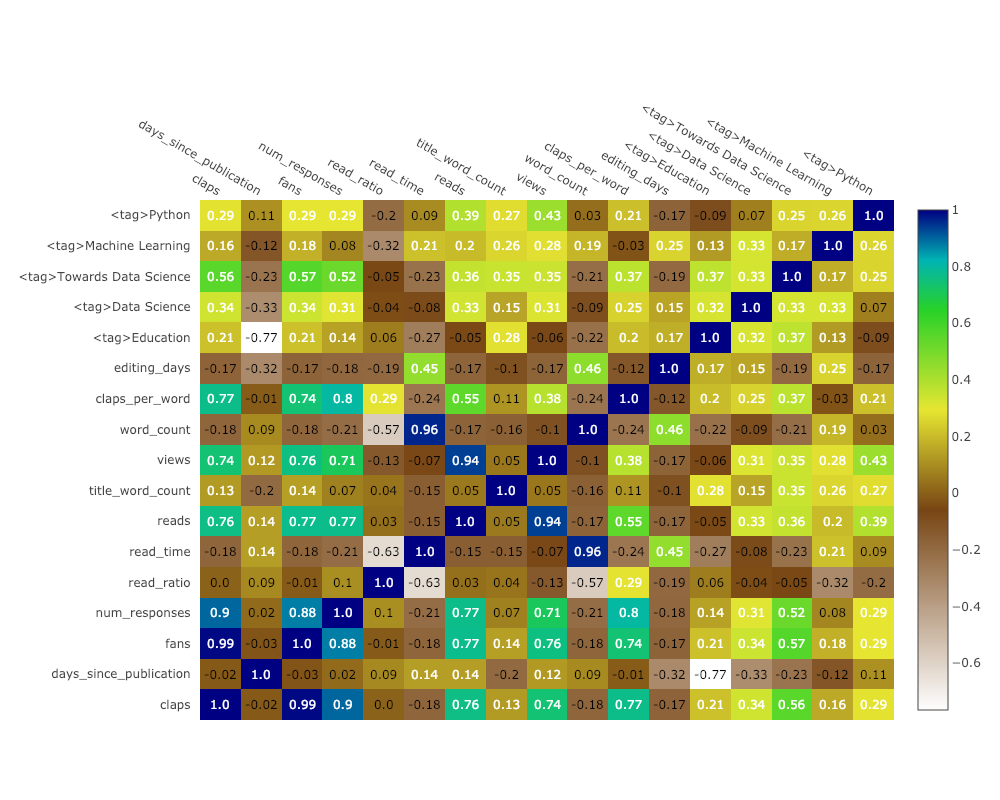
带标注热图
自定义主题
除了层出不穷的各种图表外,Cufflinks 还提供了许多不同的着色主题,方便你轻松切换各种不同的图表风格。下面两张图分别是“太空”主题和“ggplot”主题:
此外,还有 3D 图表(曲面和泡泡):
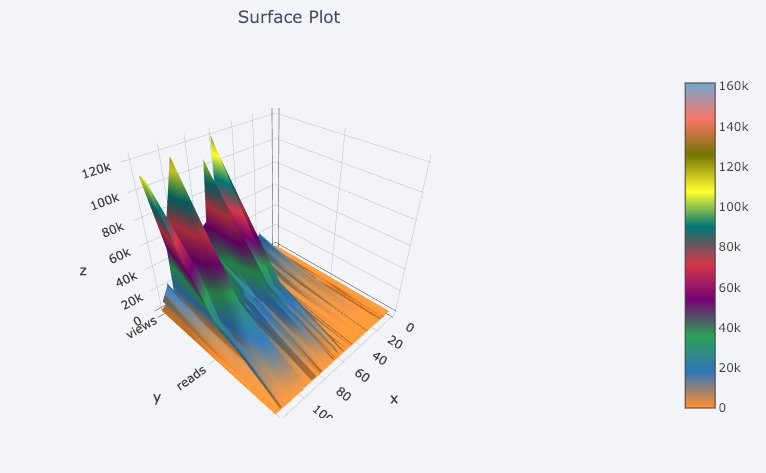
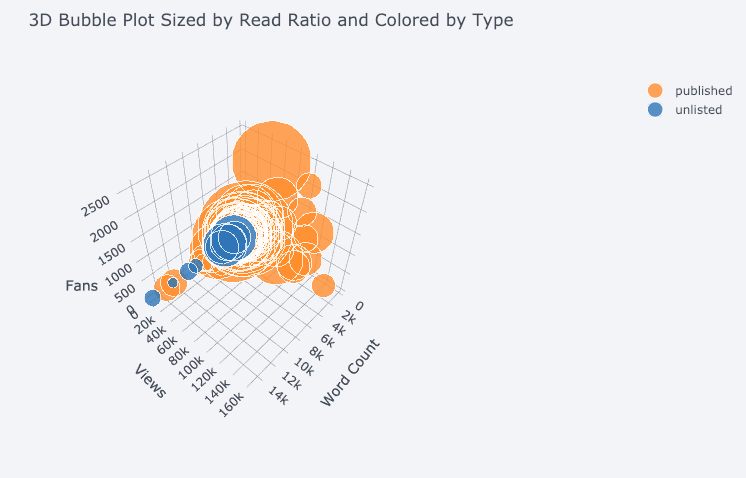
对有兴趣研究的用户来说,做张饼图也不是什么难事:
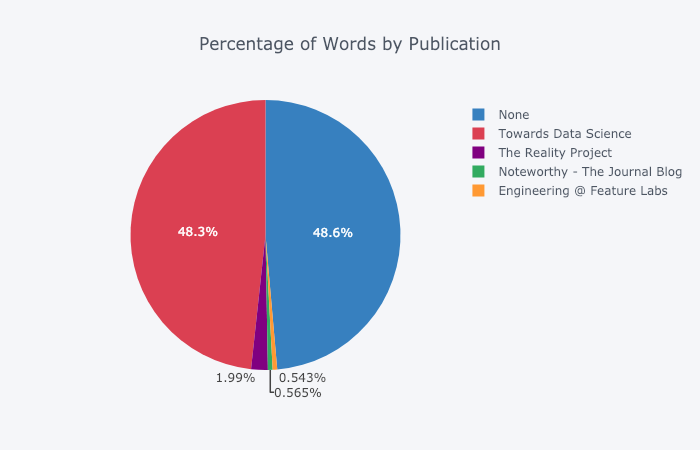
在不同刊物上发表的文字数量百分比
在 Plotly 图表工坊(Plotly Chart Studio)里编辑
当你在 Jupyter Notebook 里生成了这些图表之后,你将会发现图表的右下角出现了一个小小的链接,写着“Export to plot.ly(发布到 plot.ly)”。如果你点击这个链接,你将会跳转到一个“图表工坊”(https://plot.ly/create/)。在这里,你可以在最终展示之前,进一步修改和润色你的图表。你可以添加标注,选择某些元素的颜色,把一切都整理清楚,生成一个超棒的图表。之后,你可以将它发布到网络上,生成一个供其他人查阅的链接。
下面两张图是我在图表工坊里制作的:
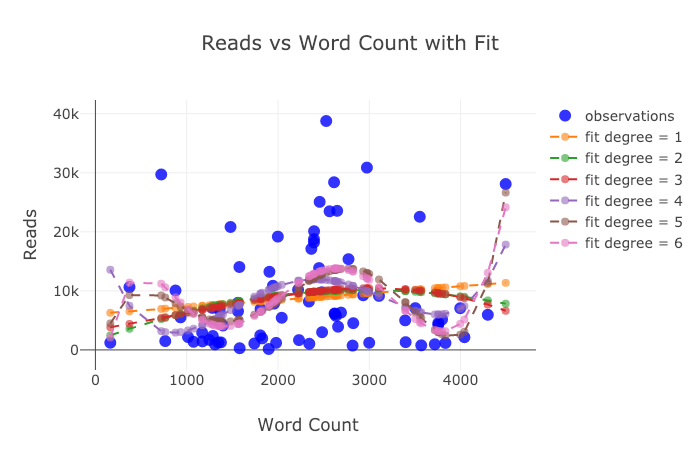
讲了这么多,想必大家都看累了吧?然而我们还并没有穷尽这个库的所有功能呢!限于篇幅,有些更棒的图表和范例,只好请大家访问 plotly 和 cufflinks 的官方文档去一一查看咯!
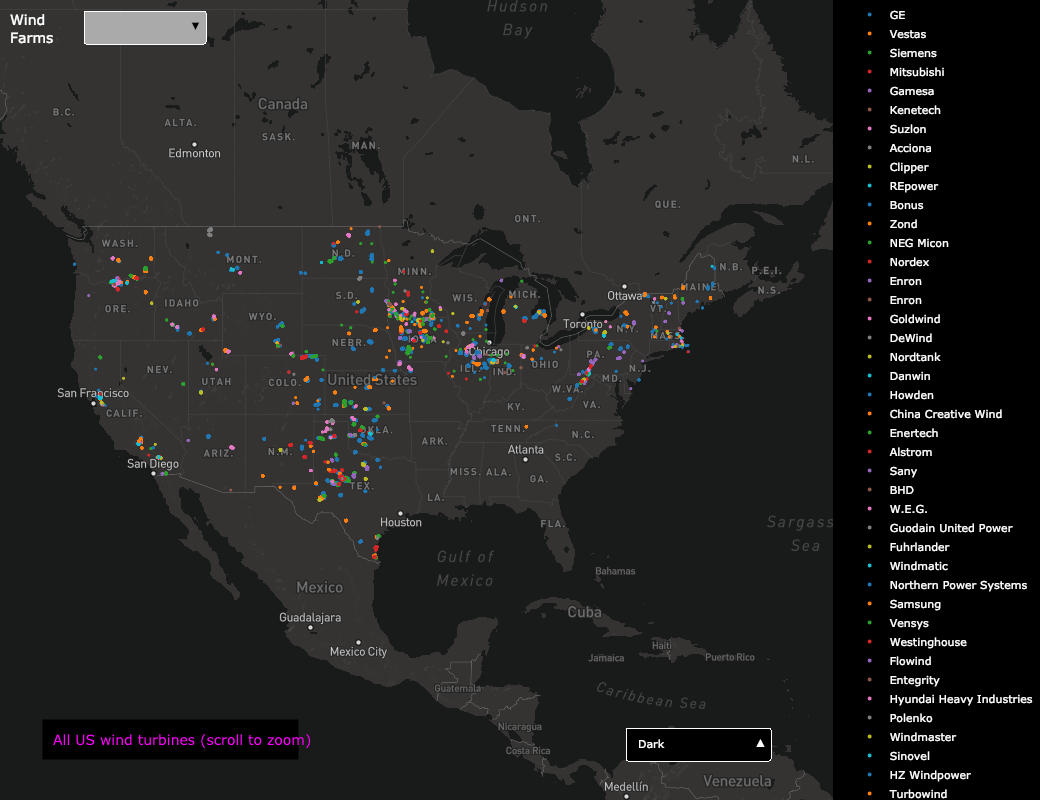
Plotly 交互式地图,显示了美国国内的风力发电场数据。来源:plot.ly
结语
关于沉没成本谬误,最糟糕的一点在于,人们往往只能在放弃之前的努力时,才能意识到自己浪费了多少时间。幸运的是,虽然我现在已经铸成大错,在 matploblib 上浪费了太多的时间,但你大可不必重蹈我的覆辙!
在选择一款绘图库的时候,你最需要的几个功能有:
- 快速探索数据所需的一行代码图表
- 拆分/研究数据所需的交互式元素
- 当需要时可以深入细节信息的选项
- 最终展示前能轻易进行定制
从现在看来,要用 Python 语言实现以上功能的最佳选择非 plotly 莫属。它让我们快速生成可视化图表,交互功能使我们更好地理解信息。我承认,绘图绝对是数据科学工作中最让人享受的部分,而 plotly 能让你更加愉悦地完成这些任务!
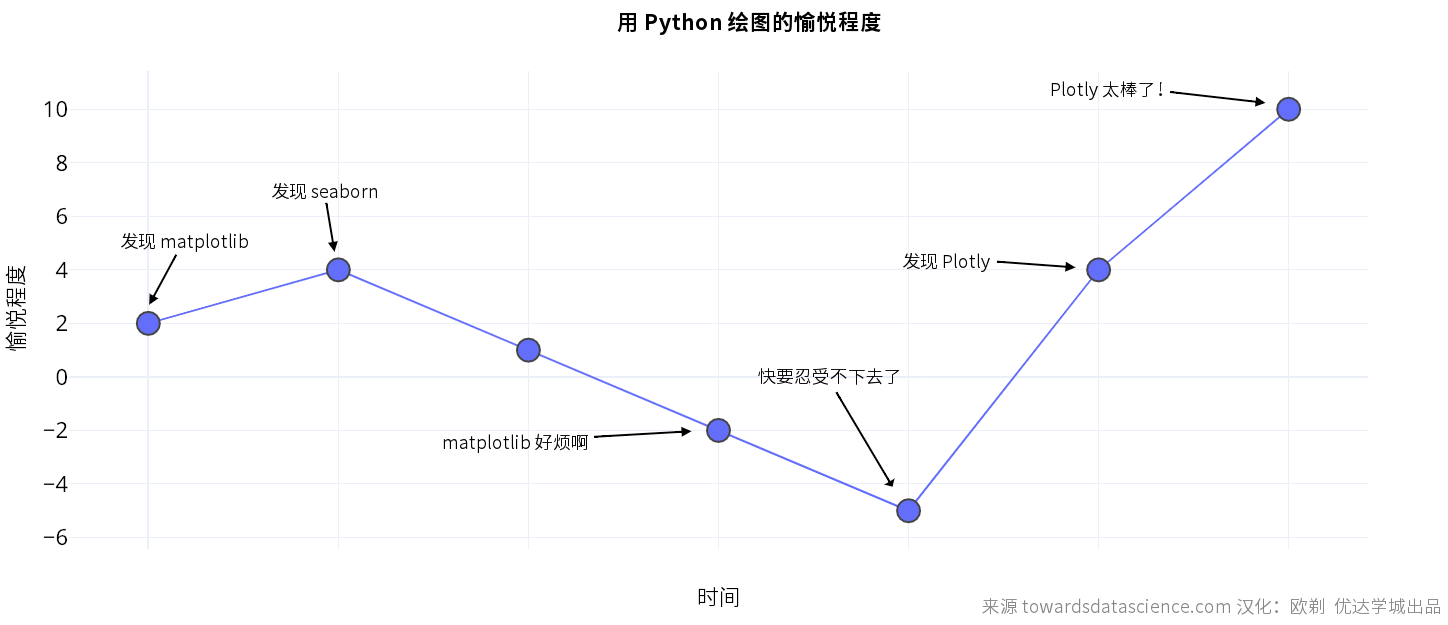
用一张图表显示一下用 Python 绘图的愉悦程度随着时间变化。
现在,2019年行将结束,赶快升级一下你的 Python 绘图库,让自己在数据科学和可视化方面变得更快、更强、更美吧!
(本文已投稿给「优达学城」。 原作: Will Koehrsen 编译:欧剃 转载请保留此信息)
编译来源: https://towardsdatascience.com/the-next-level-of-data-visualization-in-python-dd6e99039d5e
标签:Udacity、Translate、Data-Science、Python