
发表日期:2020-03-09
亚马逊数据科学家面试题集锦
—— 8 条新手必看的基础问题
作者:Terence Shin

图片来源:Unsplash,摄影 Christian Wiediger
作为顶尖科技巨头,亚马逊的数据科学岗位是许多业内新人的奋斗目标,而他们的面试题也往往指明了需要重点理解掌握的数据科学领域知识。今天,优达菌给你整理了八道数据科学面试真题,一起来看看吧!
问:现有 9 颗外表完全一样的弹球,已知其中一颗的重量略大,其他 8 颗重量都相等。试问你最少需要在天平上称几次,才能找出略重的那一颗?
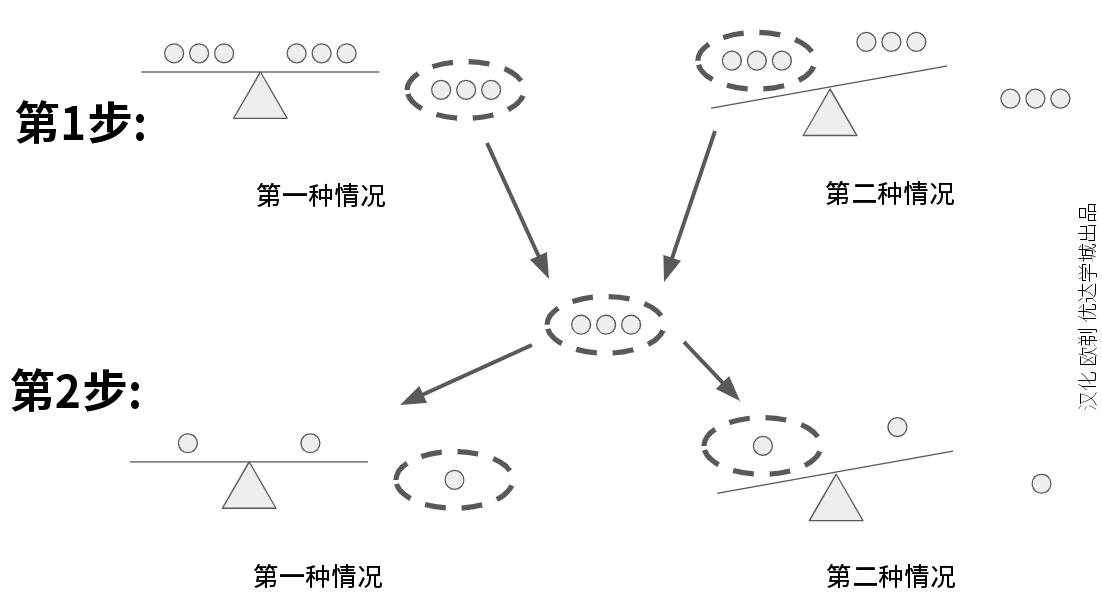
答:至少需要称两次,见上图:
- 先将 9 颗弹球随机分为 3 组,每组 3 颗,并任选其中两组上天平,比较其重量。如果天平平衡(第一种情况),则可知较重的一颗在未称过的分组中;如果天平不平衡(第二种情况),则可知较重的一颗在较重的那一组中。
- 对较重的这一组中的 3 颗弹球,重复第一步的操作,也就是每组只有 1 颗。如果天平平衡,则较重的球是未上称的第三颗;如果天平不平衡,则较重的一颗就找到了。
问:在代价函数中,凸函数和非凸函数有什么区别;代价函数为非凸函数时,说明了什么?
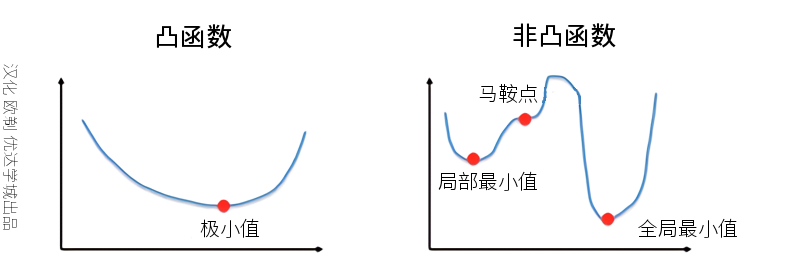
答:
- 凸函数:在函数图象上取任意两点,如果连接这两点的线段总在函数图象在这两点之间的部分的上方,那么这个函数就是凸函数。
- 非凸函数:在函数图象上取任意两点,连接这两点的线段可能会与函数图像相交。函数图像往往看起来是“波动起伏的”。
当代价函数是非凸函数时,说明模型找到的最小值有可能是局部最小值,而不一定是全局最小值。从优化的角度来说,这对机器学习模型通常是不好的。
问:什么是过拟合?
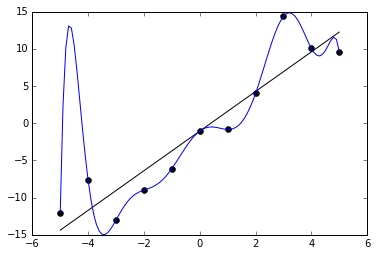
答:过拟合是指模型过于精确地“匹配”特定数据集,导致模型的方差大、偏差小的问题。这将导致过拟合的模型无法良好地拟合新的数据点——虽然它在现有的训练数据上非常精确。
问:如果调整亚马逊 Prime 会员费,会对市场产生什么样的影响?
注:这是一道开放性问题,没有 100% 准确的答案,下面是我个人的解答,仅供参考。
答:以 Prime 会员费上涨的情况为例,将有两类群体受到影响:买家和卖家。
对买家来说,会员费上涨的影响将最终取决于买家在需求上的价格弹性。当价格弹性较高时,固定的会员费上涨比例将带来较大的需求减少;当价格弹性较低时,需求的减少就没那么多。继续购买 Prime 会员的买家将可能会是亚马逊最忠实、最活跃的客户——他们也可能对支持 Prime 会员的商品更加重视。
卖家会受到一定的打击,因为在这种情况下,购买亚马逊 Prime 商品的开支更高了。也就是说,有的产品将会受到更严重的打击,而有的商品可能完全不受影响。亚马逊最忠实的客户购买的那些高端产品可能不会受到太大影响,比如电子产品等。
问:简述决策树、SVM 和“随机森林”的定义,并说出他们的优缺点。
答:
决策树:一个树形的预测模型,使模型基于一个或多个状况,选择不同的决策。
- 优点:容易实现,直观,能处理缺失值
- 缺点:偏差大,不准确
SVM:支持向量机(Support Vector Machine)是一种分类技术,它能在两类数据中找到一个区分度最好的超平面或是边界,以将两类数据区分开来。对于两类数据来说,可能有多个平面可以进行分类,但只有一个平面能最大化它们的区别。
- 优点:在高维度下很准确
- 缺点:有过拟合倾向,不能直接得出概率预测
随机森林:一个包含多个决策树的集成学习技术。随机森林算法使用原始数据集的一些样本数据训练许多不同的决策树,并在决策树的每一步中随机选择变量的子集。最后随机森林将选择所有决策树的预测结果中数量最多的结果。
- 优点:能得到更高的准确率,能处理缺失值,无需特征选择,能判断特征的重要程度
- 缺点:是个黑箱过程,计算密集度高
问:为什么降维操作很重要?
答:降维是减少数据集里特征数量的过程,它的重要性在于,你需要减少模型中变量的数量,以避免过度拟合。
维基百科上列出了降维操作的四大优势(全文):
- 降维能减少算法所需的时间和存储空间。
- 剔除多重共线性,使机器学习模型参数更容易被解释。
- 降维到足够低维度后的数据(例如 2D 或 3D)更容易被可视化。
- 避免了维数灾难现象。
问:列出一件商品的概率,在 A 处为 0.6,而 B 处为 0.8,则该物品在亚马逊网站上显示的概率是多少?
答:假设在亚马逊网站上,有两个地方都能买到同一件商品,其中在 A 处能找到的概率为 0.6,而 B 处为 0.8。那么在整个网站上能找到这个商品的概率可以如下分析:
设找到物品的概率为 P,则 P(A) = 0.6,P(B) = 0.8,假设它们是相互独立的(也就是两个事件发生的概率彼此不影响),则有下列公式:
- P(A 或 B) = P(A) + P(B) — P(A 和 B 同时发生)
- P(A 或 B) = 0.6 + 0.8 - (0.6*0.8)
- P(A 或 B) = 0.92
问:Boosting 是什么?
Boosting,即提升算法,是降低模型偏差和差异性以改善模型的集成算法。它本质上是对弱学习算法进行训练,通过向之前的算法学习,进行不断迭代并改进,最终将弱学习算法转变为强学习算法的过程。
结语
好了,上面就是今天要介绍的 8 道亚马逊数据科学面试题和对应的解答,希望能对你有所帮助!欢迎在下面留言发表你的感想!
(本文已投稿给「优达学城」。 原作: Terence Shin 翻译:欧剃 转载请保留此信息)
编译来源: https://towardsdatascience.com/amazon-data-scientist-interview-practice-problems-15b9b86e86c6
标签:Udacity、Translate、Data-Science、Machine-Learning、Python